قطرنة كريلوف الكمومية
في هذا الدرس حول قطرنة كريلوف الكمومية (KQD) سنجيب على الأسئلة التالية:
- ما هو أسلوب كريلوف بشكل عام؟
- لماذا يعمل أسلوب كريلوف وفي أي ظروف؟
- ما الدور الذي تلعبه الحوسبة الكمومية هنا؟
الجزء الكمومي من الحسابات مستند بشكل رئيسي إلى العمل الوارد في المرجع [1].
يقدم الفيديو أدناه لمحة عامة عن أساليب كريلوف في الحوسبة الكلاسيكية، ويوضح مسوّغات استخدامها، ويشرح كيف يمكن للحوسبة الكمومية أن تلعب دوراً في هذا المسار. يقدم النص التالي مزيداً من التفاصيل، وينفذ أسلوب كريلوف كلاسيكياً وعبر حاسوب كمومي.
1. مقدمة إلى أساليب كريلوف
يمكن أن يشير أسلوب الفضاء الجزئي لكريلوف إلى أي من عدة أساليب مبنية حول ما يُعرف بـ فضاء كريلوف الجزئي. المراجعة الشاملة لهذه الأساليب تتجاوز نطاق هذا الدرس، لكن المراجع [2-4] يمكنها أن تقدم خلفية أعمق بكثير. هنا سنركز على ماهية فضاء كريلوف الجزئي، وكيف ولماذا يفيد في حل مسائل القيم الذاتية، وأخيراً كيف يمكن تطبيقه على حاسوب كمومي.
التعريف: بالنظر إلى مصفوفة متماثلة وموجبة شبه محددة ، فإن فضاء كريلوف من الرتبة هو الفضاء الممتد بالمتجهات التي يتم الحصول عليها بضرب قوى متصاعدة للمصفوفة ، حتى ، في متجه مرجعي .
رغم أن المتجهات أعلاه تمتد لتكوّن ما نسميه فضاء كريلوف الجزئي، لا يوجد سبب يجعلها متعامدة. كثيراً ما يُلجأ إلى عملية تعامد تدريجية مشابهة لـ إجراء غرام-شميدت للتعامد. هنا تكون العملية مختلفة قليلاً، إذ يُجعل كل متجه جديد متعامداً مع المتجهات الأخرى فور توليده. في هذا السياق تُسمى هذه العملية تكرار أرنولدي. ابتداءً من المتجه الأولي ، يُولَّد المتجه التالي ، ثم يُضمن أن هذا المتجه الثاني متعامد مع الأول بطرح إسقاطه على . أي:
يسهل الآن التحقق من أن ، إذ:
نكرر الأمر نفسه للمتجه التالي، مضمنين تعامده مع المتجهين السابقين:
إذا كررنا هذه العملية لجميع المتجهات الـ ، نحصل على أساس متعامد ومعيّاري تام لفضاء كريلوف. لاحظ أن عملية التعامد ستنتج صفراً حين ، لأن متجهاً متعامداً يمتد بالضرورة ليملأ الفضاء بأكمله. كذلك ستنتج صفراً إذا كان أي متجه شعاعاً ذاتياً للمصفوفة ، إذ ستكون جميع المتجهات اللاحقة مضاعفات لذلك المتجه.
1.1 مثال بسيط: كريلوف يدوياً
لنسر خطوة بخطوة في توليد فضاء كريلوف الجزئي على مصفوفة صغيرة جداً، كي نرى العملية بوضوح. نبدأ بالمصفوفة الأولية التي تهمنا:
في هذا المثال الصغير، يمكننا تحديد الأشعة الذاتية والقيم الذاتية بسهولة حتى يدوياً. نعرض هنا الحل العددي.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
نسجلها هنا للمقارنة لاحقاً:
نريد دراسة كيفية عمل هذه العملية (أو إخفاقها) كلما زدنا بُعد فضاء كريلوف الجزئي . لهذا الغرض، سنطبق هذه الخطوات:
- توليد فضاء جزئي من الفضاء الكامل للمتجهات، ابتداءً من متجه مختار عشوائياً (نسميه إن كان معيّاراً بالفعل كما في الأعلى).
- إسقاط المصفوفة الكاملة على ذلك الفضاء الجزئي، وإيجاد القيم الذاتية للمصفوفة المُسقَطة .
- زيادة حجم الفضاء الجزئي بتوليد مزيد من المتجهات، مضمنين أنها متعامدة ومعيّارية، باستخدام عملية مشابهة لتعامد غرام-شميدت.
- إسقاط على الفضاء الجزئي الأكبر وإيجاد القيم الذاتية للمصفوفة الناتجة .
- تكرار ذلك حتى تتقارب القيم الذاتية (أو في هذه الحالة التوضيحية، حتى تولّد متجهات تمتد لتملأ الفضاء الكامل للمصفوفة الأصلية ).
لا تحتاج عملية تنفيذ أسلوب كريلوف الاعتيادية إلى حل مسألة القيم الذاتية للمصفوفة المُسقطة عند كل فضاء كريلوف جزئي أثناء بنائه. يمكنك بناء الفضاء الجزئي بالبُعد المطلوب، وإسقاط المصفوفة عليه، وقطرنة المصفوفة المُسقطة. الإسقاط والقطرنة عند كل بُعد للفضاء الجزئي يُجرى فقط للتحقق من التقارب.
البُعد :
نختار متجهاً عشوائياً، لنقل:
إن لم يكن معيّاراً، نعيّاره.
نُسقط الآن مصفوفتنا على الفضاء الجزئي لهذا المتجه الواحد:
هذا هو إسقاط المصفوفة على فضاء كريلوف الجزئي حين يحتوي متجهاً واحداً فقط، . القيمة الذاتية لهذه المصفوفة هي 4 بشكل بديهي. يمكننا اعتبار ذلك تقديراً من الدرجة الصفرية للقيم الذاتية (متجه واحد في هذه الحالة) للمصفوفة . رغم أنه تقدير ضعيف، إلا أنه في الرتبة الصحيحة للحجم.
البُعد :
نولّد الآن المتجه التالي في فضاءنا الجزئي عبر تطبيق على المتجه السابق:
نطرح الآن إسقاط هذا المتجه على متجهنا السابق لضمان التعامد.
إن لم يكن معيّاراً، نعيّاره. في هذه الحالة كان المتجه معيّاراً بالفعل، لذا:
نُسقط الآن مصفوفتنا A على الفضاء الجزئي لهذين المتجهين:
لا يزال علينا تحديد القيم الذاتية لهذه المصفوفة. لكن هذه المصفوفة أصغر قليلاً من المصفوفة الكاملة. في المسائل التي تنطوي على مصفوفات ضخمة جداً، قد يكون العمل مع هذا الفضاء الجزئي الأصغر ميزة كبيرة.
رغم أن هذا لا يزال تقديراً غير دقيق، إلا أنه أفضل من التقدير من الدرجة الصفرية. سنواصل التكرار لمرة واحدة أخرى للتأكد من وضوح العملية. غير أن هذا يُقلل من الهدف الرئيسي للأسلوب، إذ سننتهي بقطرنة مصفوفة 3×3 في التكرار التالي، مما يعني أننا لم نوفر وقتاً أو قدرة حسابية.
البُعد :
نولّد الآن المتجه التالي في فضاءنا الجزئي عبر تطبيق A على المتجه السابق:
نطرح الآن إسقاط هذا المتجه على كلا المتجهين السابقين لضمان التعامد.
إن لم يكن معيّاراً، نعيّاره. في هذه الحالة كان المتجه معيّاراً بالفعل، لذا:
نُسقط الآن مصفوفتنا على الفضاء الجزئي لهذه المتجهات:
نحدد الآن القيم الذاتية:
هذه القيم الذاتية هي بالضبط القيم الذاتية للمصفوفة الأصلية . لا بد أن يكون الأمر كذلك، إذ وسّعنا فضاء كريلوف الجزئي ليمتد على الفضاء الكامل للمتجهات للمصفوفة الأصلية .
في هذا المثال، قد لا يبدو أسلوب كريلوف أسهل بشكل واضح من القطرنة المباشر. بالفعل، كما سنرى في الأقسام اللاحقة، لا يكون أسلوب كريلوف مفيداً إلا فوق بُعد معين للمصفوفة؛ والغرض من ذلك هو مساعدتنا في حل مسائل القيم الذاتية/الأشعة الذاتية للمصفوفات ذات الأبعاد الضخمة للغاية.
هذا هو المثال الوحيد الذي سنعرضه منجزاً "يدوياً"، لكن القسم 2 أدناه يعرض أمثلة حسابية.
توضيح المصطلحات
من المفاهيم الخاطئة الشائعة الاعتقاد بأن هناك فضاء كريلوف واحداً فقط لمسألة معينة. لكن بما أن هناك متجهات أولية كثيرة يمكن تطبيق مصفوفتنا عليها، فهناك فضاءات كريلوف جزئية كثيرة ممكنة. سنستخدم عبارة "فضاء كريلوف" للإشارة إلى فضاء كريلوف جزئي محدد تم تعريفه مسبقاً لمثال بعينه. أما في أساليب حل المسائل بشكل عام، فسنشير إلى "فضاء كريلوف جزئي". توضيح أخير: من الصحيح الإشارة إلى "فضاء كريلوف". كثيراً ما يُسمى "فضاء كريلوف الجزئي" بسبب استخدامه في سياق إسقاط المصفوفات من الفضاء الأصلي إلى فضاء جزئي. واستمراراً في هذا السياق، سنشير إليه في معظم الأحيان بالفضاء الجزئي.
تحقق من فهمك
اقرأ الأسئلة أدناه، فكّر في إجابتك، ثم انقر على المثلث للكشف عن كل حل.
اشرح لماذا ليس من (أ) المفيد، و(ب) الممكن توسيع بُعد فضاء كريلوف الجزئي إلى أبعد من البُعد للمصفوفة موضع الاهتمام.
الجواب:
(أ) بما أننا نُعيّار المتجهات بالتعامد عند توليدها، فإن مجموعة من متجهاً من هذا القبيل تشكّل أساساً كاملاً، بمعنى أن تركيباً خطياً منها يمكن استخدامه لبناء أي متجه في الفضاء. (ب) تتكون عملية التعامد من طرح إسقاط متجه جديد على جميع المتجهات السابقة. إذا امتدت جميع المتجهات السابقة لتملأ الفضاء الكامل للمتجهات، فإن طرح الإسقاطات على الفضاء الجزئي الكامل سيُعطي دائماً متجهاً صفرياً.
لنفترض أن زميلاً باحثاً يستعرض أسلوب كريلوف مطبقاً على مصفوفة توضيحية صغيرة أمام بعض الزملاء. ويخطط هذا الزميل لاستخدام المصفوفة والمتجه الأولي:
و
هل ثمة خطأ في ذلك؟ كيف تنصح زميلك؟
الجواب:
اختار زميلك عن غير قصد شعاعاً ذاتياً كمتجهه الأولي. تطبيق المصفوفة على المتجه الأولي سيُعيد نفس المتجه ببساطة مضروباً في القيمة الذاتية. لن يُنشئ ذلك فضاء جزئياً متصاعد الأبعاد. انصح زميلك باختيار متجه أولي مختلف، مع التأكد من أنه ليس شعاعاً ذاتياً.
طبّق أسلوب كريلوف على المصفوفة أدناه، مع اختيار متجه أولي مناسب جديد. اكتب تقديرات القيمة الذاتية الدنيا عند الدرجة الصفرية والأولى لفضاء كريلوف الجزئي.
الجواب:
هناك إجابات كثيرة ممكنة تبعاً لاختيار المتجه الأولي. سنختار:
للحصول على نطبق مرة واحدة على ، ثم نجعل متعامداً مع .
عند الدرجة الصفرية، الإسقاط على فضاء كريلوف الجزئي هو:
عند الدرجة الأولى، الإسقاط على فضاء كريلوف الجزئي هو:
يمكن إنجاز ذلك يدوياً، لكنه أسهل باستخدام numpy:
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
الناتج:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
تقدير القيمة الذاتية الدنيا هو -0.414.
1.2 أنواع أساليب كريلوف
يمكن أن تشير "أساليب الفضاء الجزئي لكريلوف" إلى أي من عدة تقنيات تكرارية تُستخدم لحل الأنظمة الخطية الكبيرة ومسائل القيم الذاتية. ما يجمعها هو أنها جميعاً تبني حلاً تقريبياً من فضاء كريلوف الجزئي:
حيث هو التخمين الأولي (انظر المرجع [5]). تتمايز هذه الأساليب في طريقة اختيار أفضل تقريب من هذا الفضاء الجزئي، موازنةً بين عوامل مثل معدل التقارب، واستخدام الذاكرة، والتكلفة الحسابية الإجمالية. يهدف هذا الدرس إلى توظيف الحوسبة الكمومية في سياق أساليب الفضاء الجزئي لكريلوف؛ والنقاش المستفيض لهذه الأساليب يتجاوز نطاقه. التعريفات الموجزة أدناه هي للسياق فحسب وتتضمن بعض المراجع للتعمق في هذه الأساليب.
أسلوب التدرج المترافق (CG): يُستخدم هذا الأسلوب لحل الأنظمة الخطية المتماثلة الموجبة المحددة[6]. يُصغّر معيار-A للخطأ عند كل تكرار، مما يجعله فعالاً بشكل خاص للأنظمة الناشئة من المعادلات التفاضلية الجزئية الإهليلجية المُقدَّرة بشكل منفصل[7]. سنستخدم هذا النهج في القسم التالي لتوضيح سبب كون فضاء كريلوف الجزئي فضاءً فعالاً للبحث فيه عن حلول محسّنة للأنظمة الخطية.
أسلوب البواقي الدنيا المعمّمة (GMRES): صُمِّم لحل الأنظمة الخطية غير المتماثلة بشكل عام. يُصغّر معيار البواقي على فضاء كريلوف عند كل تكرار، مما يجعله قوياً لكنه قد يستهلك ذاكرة كبيرة للأنظمة الضخمة[7].
أسلوب البواقي الدنيا (MINRES): يُستخدم هذا الأسلوب لحل الأنظمة الخطية المتماثلة غير المحددة. مشابه لـ GMRES لكنه يستغل تماثل المصفوفة لتقليل التكلفة الحسابية[8].
من الأساليب الأخرى الجديرة بالذكر: أسلوب التعامد الكامل (FOM)، الذي يرتبط ارتباطاً وثيقاً بأسلوب أرنولدي لمسائل القيم الذاتية، وأسلوب التدرج المترافق ثنائي الاتجاه (BiCG)، وأسلوب تقليص البُعد المستحث (IDR).
1.3 لماذا يعمل أسلوب الفضاء الجزئي لكريلوف
هنا سنوضح أن أسلوب الفضاء الجزئي لكريلوف يُعدّ طريقة فعالة لتقريب القيم الذاتية للمصفوفات عبر التحسين التكراري لتقريبات الأشعة الذاتية، من منظور الانحدار الأشد. سنجادل بأنه بالنظر إلى تخمين أولي لحالة الأساس، فإن فضاء التصحيحات المتعاقبة لذلك التخمين الأولي الذي يحقق أسرع تقارب هو بالضبط فضاء كريلوف الجزئي. نتوقف دون الوصول إلى إثبات دقيق لسلوك التقارب.
لنفترض أن مصفوفتنا موضع الاهتمام متماثلة وموجبة محددة. هذا يجعل حجتنا أكثر ارتباطاً بأسلوب CG أعلاه. لا نفترض هنا أي شيء عن التخلخل؛ كما لا ندّعي أن يجب أن تكون إرميتية (وهو ما تحتاجه إذا كانت هاميلتونياً).
نسعى عادةً لحل مسألة بالصيغة:
يمكن تصوّر أن حيث ثابت، كما في مسألة القيم الذاتية. لكن صياغة مسألتنا تبقى أكثر عمومية في الوقت الحالي.
نبدأ بالمتجه كحل تقريبي. رغم وجود أوجه تشابه بين هذا التخمين و في القسم 1.1، لا نستغلها هنا. تخميننا يحتوي خطأً نسميه :
نُعرّف أيضاً البقية :
هنا نستخدم الكبيرة للتمييز بين البقية وبُعد فضاء كريلوف الجزئي .

نريد الآن إجراء خطوة تصحيح بالصيغة:
التي نأمل أن تحسّن تقريبنا. هنا متجه لم يُحدَّد بعد. ليكن الخطأ بعد التصحيح. عندئذ:

نهتم بكيفية تصرف خطئنا عند التحويل بمصفوفتنا. لذا لنحسب معيار-A للخطأ، أي:
حيث استخدمنا تماثل وأيضاً أن . هنا ثابت مستقل عن . كما ذُكر في القسم 1.2، معيار-A للخطأ ليس الكمية الوحيدة التي قد نختار تصغيرها، لكنه خيار جيد. نريد أن نرى كيف تتغير هذه الكمية باختيارنا لمتجهات التصحيح . لذا نُعرّف الدالة بوضع:
هي مجرد الخطأ كدالة في التصحيح مقيساً بمعيار-A. ومن ثَمّ نريد اختيار بحيث يكون أصغر ما يمكن. لهذا الغرض نحسب تدرج . باستخدام تماثل لدينا:
يشير التدرج نحو اتجاه الصعود الأشد، مما يعني أن عكسه يعطينا الاتجاه الذي تنخفض فيه الدالة بشكل أكبر: اتجاه الانحدار الأشد. عند تخميننا الأولي ، حيث ، لدينا: وهكذا، تنخفض الدالة بشكل أكبر في اتجاه البقية . لذا سيستفيد اختيارنا الأولي بشكل أكبر من إضافة المتجه لبعض ثابت .
في الخطوة التالية، نختار مجدداً متجهاً ونضيف قيمته إلى التقريب الحالي. باستخدام نفس المنطق السابق نختار لبعض ثابت . نواصل بهذا الأسلوب، بحيث يكون التكرار الـ لمتجهنا:
بالمعنى المكافئ، نريد بناء الفضاء الذي نختار منه تقديراتنا المحسّنة بإضافة ، ، وهكذا بالترتيب. يقع المتجه المُقدَّر الـ في:
الآن، باستخدام العلاقة التالية:
نرى أن:
أي أن الفضاء الذي نبنيه والذي يُقرّب الحل الصحيح بأكفأ شكل هو بالضبط الفضاء المبني عبر التطبيق المتعاقب للمصفوفة على . فضاء كريلوف الجزئي هو الفضاء الممتد بمتجهات اتجاهات الانحدار الأشد المتعاقبة.
أخيراً، نؤكد مجدداً أننا لم نُقدم أي ادعاءات رقمية حول تدرّج هذا النهج، ولم نناقش المنفعة المقارنة للمصفوفات المتخلخلة. هذا فقط لتوضيح مسوّغات استخدام أساليب الفضاء الجزئي لكريلوف وإضفاء بعض الحدس عليها. سنستعرض الآن سلوك هذه الأساليب عدديّاً.
تحقق من فهمك
اقرأ السؤال أدناه، فكّر في إجابتك، ثم انقر على المثلث للكشف عن الحل.
في المسار الموضح أعلاه، اقترحنا تصغير -norm للخطأ. ما الكميات الأخرى التي يمكن أخذها بعين الاعتبار عند السعي إلى إيجاد الحالة الأساسية وقيمتها الذاتية؟
الإجابة:
يمكن تصوُّر استخدام متجه البواقي بدلاً من -norm للخطأ. قد تكون هناك حالات يكون فيها النظر في متجه الخطأ نفسه مفيداً.
2. طرق كريلوف في الحوسبة الكلاسيكية
في هذا القسم، سنُنفّذ تكرارات أرنولدي حسابياً لنتمكن من الاستفادة من الفضاء الجزئي لكريلوف في حل مسائل القيم الذاتية. سنطبّق هذا أولاً على مثال صغير النطاق، ثم نفحص كيف يتغير زمن الحوسبة مع تزايد حجم المصفوفة. الفكرة الجوهرية هنا هي أن توليد المتجهات التي تمتد عليها فضاء كريلوف سيكون المساهم الأكبر في إجمالي الزمن الحسابي المطلوب. أما الذاكرة المطلوبة فتتفاوت بين طرق كريلوف المختلفة، لكن قيودها يمكن أن تحدّ من استخدام طرق كريلوف التقليدية.
2.1 مثال بسيط صغير النطاق
في سياق إنشاء فضاء كريلوف الجزئي، نحتاج إلى تعامُد المتجهات في الفضاء الجزئي. لنُعرّف دالة تأخذ متجهاً معروفاً من الفضاء الجزئي vknown (لا يُفترض أنه مُقيَّس) ومتجهاً مرشحاً لإضافته إلى الفضاء الجزئي vnext، وتجعل vnext متعامداً مع vknown ومُقيَّساً. لنُعرّف أيضاً دالة تمر عبر هذه العملية لجميع المتجهات المعروفة في فضاء كريلوف الجزئي لضمان حصولنا على مجموعة متعامدة تماماً.
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
الآن لنُعرّف دالة تبني فضاءً جزئياً لكريلوف يكبر تكرارياً حتى يمتد فضاء متجهات كريلوف على الفضاء الكامل للمصفوفة الأصلية. سيمكّننا هذا من رؤية مدى دقة القيم الذاتية التي نحصل عليها باستخدام طريقة الفضاء الجزئي لكريلوف مقارنةً بالقيم الدقيقة، كدالة في بُعد الفضاء الجزئي لكريلوف. والجدير بالذكر أن الدالة krylov_full_build تُعيد متجهات كريلوف، وهاميلتونيات الإسقاط، والقيم الذاتية، والزمن المطلوب.
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
سنختبر هذا على مصفوفة لا تزال صغيرة نسبياً، لكنها أكبر مما قد نرغب في معالجته يدوياً.
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
يمكننا التحقق من صحة دوالنا بالتأكد من أن القيم الذاتية الناتجة في الخطوة الأخيرة (حين يكون فضاء كريلوف هو الفضاء المتجهي الكامل للمصفوفة الأصلية) تتطابق تماماً مع تلك الناتجة عن القطرنة العددي الدقيق:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
نجح الأمر. بالطبع، ما يهمنا فعلاً هو مدى جودة التقريب كدالة في بُعد الفضاء الجزئي لكريلوف. ولأننا كثيراً ما نهتم بإيجاد الحالات الأساسية وأصغر القيم الذاتية (ولأسباب جبرية أخرى تُشرح أدناه)، فلننظر إلى تقديرنا لأصغر قيمة ذاتية كدالة في بُعد الفضاء الجزئي لكريلوف. أي:
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
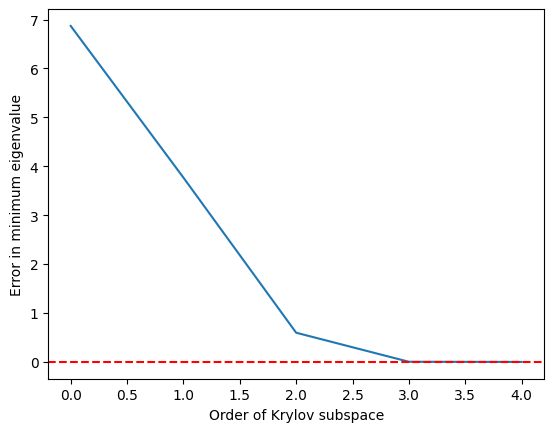
نلاحظ أن أصغر قيمة ذاتية تُحسب بدقة معقولة حين ينمو الفضاء الجزئي لكريلوف إلى ، وتكون مثالية عند .
2.2 تحجيم الزمن مع بُعد المصفوفة
لنتحقق من أن طريقة كريلوف يمكن أن تكون أفضل من محلّلات القيم الذاتية العددية الدقيقة بالطريقة التالية:
- إنشاء مصفوفات عشوائية (غير متفرقة، وليست التطبيق المثالي لـ KQD)
- تحديد القيم الذاتية باستخدام طريقتين: مباشرةً باستخدام NumPy وباستخدام فضاء كريلوف الجزئي.
- نختار حداً فاصلاً لدقة القيم الذاتية المطلوبة قبل قبول تقديرات كريلوف.
- مقارنة الزمن الفعلي اللازم للحل بالطريقتين.
تحفظات: كما سنناقش بالتفصيل أدناه، تُطبَّق خوارزمية KQD على أفضل وجه على العوامل التي تمثيلاتها المصفوفية متفرقة و/أو يمكن كتابتها باستخدام عدد صغير من مجموعات عوامل باولي المتبادلة التبديل. المصفوفات العشوائية التي نستخدمها هنا لا تنطبق عليها هذه الصفة. هي مفيدة فقط لاستكشاف النطاق الذي قد تكون عنده طرق كريلوف الكلاسيكية نافعة. ثانياً، عند استخدام طريقة كريلوف، سنحسب القيم الذاتية باستخدام فضاءات جزئية لكريلوف بأبعاد متعددة مختلفة. وسنُسجّل الزمن اللازم لأصغر فضاء جزئي لكريلوف يحقق الدقة المطلوبة لقيمة الحالة الأساسية الذاتية. مرة أخرى، هذا يختلف بعض الشيء عن حل مسألة يستعصي حلها على محلّلات القيم الذاتية الدقيقة، إذ نستخدم الحل الدقيق لتقييم البُعد المطلوب.
نبدأ بتوليد مجموعة من المصفوفات العشوائية.
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
الآن نُقطّر كل مصفوفة مباشرةً باستخدام numpy، ونحسب الزمن اللازم للمقارنة لاحقاً.
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
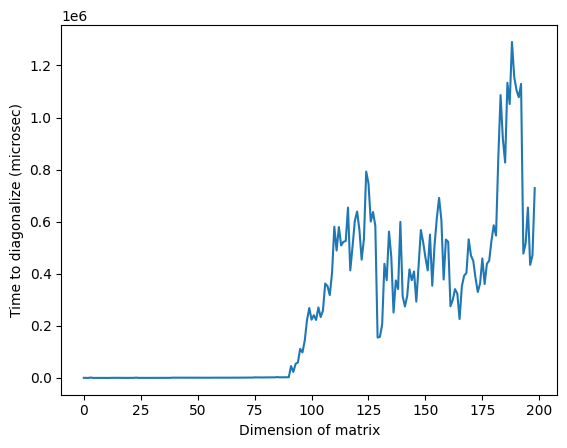
لاحظ أن الزمن المرتفع بشكل غير عادي في الصورة أعلاه عند بُعد تقريبي يبلغ 125 قد يكون راجعاً إلى الطابع العشوائي للمصفوفات أو إلى التنفيذ على المعالج الكلاسيكي المستخدم، لكنه لا يتكرر عند إعادة التشغيل. إعادة تشغيل الكود ستُنتج ملفاً شخصياً مختلفاً مع قمم شاذة مختلفة.
الآن لكل مصفوفة سنبني فضاء كريلوف الجزئي ونحسب القيم الذاتية خطوةً خطوة. في كل خطوة، سنتحقق مما إذا كانت أصغر قيمة ذاتية قد تم الحصول عليها ضمن الخطأ المطلق المحدد. الفضاء الجزئي الذي يُعطي القيم الذاتية ضمن الخطأ المحدد لأول مرة هو الفضاء الذي سنسجّل وقت الحوسبة عنده. قد يستغرق تنفيذ هذه الخلية عدة دقائق حسب سرعة المعالج. يمكنك تجاوز التنفيذ أو تقليل الحد الأقصى لأبعاد المصفوفات المُقطَّرة. الاطلاع على النتائج المحسوبة مسبقاً كافٍ.
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
لنرسم الأزمنة التي حصلنا عليها للطريقتين مقارنةً:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

هذه هي الأزمنة الفعلية المطلوبة، لكن لأغراض المناقشة، لنُخمّد هذه المنحنيات بالمتوسط على عدد قليل من النقاط/أبعاد المصفوفات المتجاورة. يتم ذلك أدناه:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

لاحظ أن الزمن اللازم لبناء فضاء كريلوف الجزئي يتجاوز في البداية الزمن اللازم للقطرنة الكامل باستخدام numpy. لكن مع نمو حجم المصفوفة، تصبح طريقة كريلوف أكثر كفاءة. وهذا صحيح حتى لو خفّضنا الخطأ المقبول، لكن الميزة تبدأ في الظهور عند حجم مصفوفة أكبر. يستحق هذا التأمل والتفكير.
التعقيد الزمني للقطرنة العددي هو (مع بعض التباين بين الخوارزميات). والتعقيد الزمني لتوليد أساس متعامد لـ متجهاً هو أيضاً . لذا فإن ميزة طريقة كريلوف لا تعود إلى استخدام أساس متعامد ، بل إلى استخدام أساس متعامد بعينه يُبرز بفعالية القيم الذاتية المطلوبة. رأينا هذا بالفعل من الدليل التخطيطي في القسم الأول من هذا الدرس، وهو أمر حاسم لضمانات التقارب في طرق كريلوف.
لنراجع ما توصلنا إليه حتى الآن:
- بالنسبة للمصفوفات الكبيرة جداً، قد تُعطي طريقة الفضاء الجزئي لكريلوف قيماً ذاتية تقريبية ضمن التفاوتات المطلوبة بشكل أسرع من خوارزميات القطرنة التقليدية.
- بالنسبة لهذه المصفوفات الكبيرة جداً، يُمثّل توليد فضاء كريلوف الجزئي الجزء الأكثر استهلاكاً للوقت في طريقة الفضاء الجزئي لكريلوف.
- لذا فإن طريقة فعّالة لتوليد فضاء كريلوف الجزئي ستكون ذات قيمة كبيرة. وهنا يدخل الحاسوب الكمي في الصورة.
تحقق من فهمك
اقرأ السؤال أدناه، فكّر في إجابتك، ثم انقر على المثلث للكشف عن الحل.
ارجع إلى الرسم البياني المُخمَّد لأزمنة القطرنة مقابل بُعد المصفوفة أعلاه.
(أ) عند أي بُعد تقريبي للمصفوفة أصبحت طريقة كريلوف أسرع، وفقاً لهذا الرسم؟
(ب) ما الجوانب في الحساب التي يمكن أن تُغيّر البُعد الذي تصبح عنده طريقة كريلوف أسرع؟
الإجابة:
(أ) قد تتباين الإجابات إذا أعدت تشغيل الحساب، لكن طريقة كريلوف تصبح أسرع عند بُعد تقريبي يتراوح بين 80 و85. (ب) ثمة إجابات كثيرة محتملة. من أهم العوامل: الدقة المطلوبة وتفرُّق المصفوفات المراد قطرنةها.
3. كريلوف عبر التطور الزمني
كل ما وصفناه حتى الآن يمكن تنفيذه كلاسيكياً. إذن كيف ومتى نستخدم الحاسوب الكمي؟ بالنسبة للمصفوفات الكبيرة جداً، يمكن أن تتطلب طريقة كريلوف أزمنة حوسبة طويلة وكميات كبيرة من الذاكرة. يتناسب الزمن اللازم لعملية المصفوفة على مع في أسوأ الحالات. حتى ضرب المصفوفات المتفرقة في متجه (الحالة الشائعة لحلّالات كريلوف الكلاسيكية) له تعقيد زمني يتناسب مع . وهذا يتم لكل متجه نريد وضعه في الفضاء الجزئي. بُعد الفضاء الجزئي عادةً ليس كسراً كبيراً من ، وغالباً يتناسب مع . لذا يتناسب توليد جميع المتجهات مع في أسوأ الحالات. وبالرغم من وجود خطوات أخرى كالتعامد، يظل هذا هو التحجيم السائد الذي يجب أخذه في الاعتبار.
تتيح لنا الحوسبة الكمية تغيير الخصائص التي تُحدد تحجيم الزمن والموارد المطلوبة. بدلاً من الاعتماد على حجم المصفوفة في كل مكان، سنرى أشياء كعدد اللقطات (shots) وعدد مصطلحات باولي غير المتبادلة التبديل التي تُشكّل الهاميلتوني. دعنا نستكشف كيف يعمل هذا.
3.1 التطور الزمني
تذكّر أن العامل الذي يُطوّر حالة كمومية زمنياً هو (ومن الشائع جداً في الحوسبة الكمية حذف من الترميز). إحدى طرق فهم وتحقيق مثل هذه الدالة الأسية لعامل ما هي النظر في توسُّعها كمتسلسلة تايلور. لاحظ أن هذه العملية المطبَّقة على متجه ابتدائي تُعطي مجماً من الحدود مع قوى متزايدة من مُطبَّقة على الحالة الابتدائية. يبدو أننا نستطيع ببساطة بناء الفضاء الجزئي لكريلوف بتطوير حالتنا الأولية زمنياً!
التحفظ يكمن في تحقيق التطور الزمني على حاسوب كمي حقيقي. كثير من مصطلحات الهاميلتوني لن تتبادل التبديل مع بعضها. لذا، بينما تقابل بعض العوامل الأسية البسيطة كـ دوائر بسيطة، فإن الهاميلتونيات العامة لا تقابل ذلك. وبما أنها تحتوي على مصطلحات غير متبادلة التبديل، لا يمكننا ببساطة تحليل الأسي إلى جداء من أسيات بسيطة، كما يمكننا فعله مع الأعداد.
لذا الأمر ليس بسيطاً، لكنه عملية مدروسة جيداً في الحوسبة الكمية. ننفّذ التطور الزمني على الحواسيب الكمية باستخدام عملية تُسمى التروتَرة (trotterization)، وهي موضوع غني في حد ذاتها[10]. لكن على مستوى عالٍ جداً، بتقسيم التطور الزمني إلى خطوات صغيرة جداً، لنقل خطوة بحجم ، نُحدّ من تأثيرات عدم تبادل تبديل المصطلحات.
حيث .
لنُسمّي الفضاء الجزئي لكريلوف من الرتبة r الذي ولّدناه في السياق الكلاسيكي باستخدام قوى H مباشرةً "فضاء كريلوف القوى" (power Krylov subspace).
الآن نُولّد فضاءً مشابهاً باستخدام عامل التطور الزمني الوحداني ؛ وسنُطلق عليه "فضاء كريلوف الوحداني" . لا يمكن توليد فضاء كريلوف القوى الذي نستخدمه كلاسيكياً مباشرةً على الحاسوب الكمي إذ إن ليس عاملاً وحدانياً. يمكن إثبات أن استخدام فضاء كريلوف الوحداني يُعطي ضمانات تقارب مشابهة لفضاء كريلوف القوى، أي أن خطأ الحالة الأساسية يتقارب بكفاءة طالما أن الحالة الابتدائية لها تداخل مع الحالة الأساسية الحقيقية لا يتلاشى أسياً، وطالما يوجد فجوة كافية بين القيم الذاتية. انظر المرجع [1] للاطلاع على مناقشة أدق للتقارب.
هنا، تُصبح قوى خطوات زمنية مختلفة (القوة لـ هي التقدم للأمام بزمن ). يمكننا تسمية عنصر الفضاء الجزئي المُطوَّر زمنياً بإجمالي زمن بـ .
يمكننا إسقاط هاميلتونيانا H على الفضاء الجزئي الوحداني لكريلوف . بعبارة أخرى، نحسب كل عنصر مصفوفي لـ في أساس . سنُشير إلى هذه المصفوفة المُسقَطة بـ .
3.2 كيفية التنفيذ على الحاسوب الكمي
تُعطى عناصر مصفوفة بالقيم المتوقعة ، التي يمكن تقديرها باستخدام الحاسوب الكمي. ضع في اعتبارك أن يمكن كتابته كمجموع من عوامل باولي على كيوبتات مختلفة، وأنه لا يمكن قياس جميع عوامل باولي في آنٍ واحد. يمكننا فرز مصطلحات باولي إلى مجموعات من المصطلحات المتبادلة التبديل وقياسها جميعاً دفعةً واحدة. لكن قد نحتاج إلى عدد كبير من هذه المجموعات لتغطية جميع المصطلحات. لذا يصبح عدد مجموعات التبديل المتبادل المتمايزة التي يمكن تقسيم المصطلحات إليها، ، أمراً مهماً.
هنا هو سلسلة باولي من الشكل أو مجموعة من سلاسل باولي المتبادلة التبديل فيما بينها. بما أنه يمكننا كتابة كمجموع من العوامل القابلة للقياس، يمكن تحقيق التعبيرات التالية لعناصر مصفوفة باستخدام Qiskit Runtime primitive Estimator.
حيث هي متجهات فضاء كريلوف الوحداني و هي مضاعفات الخطوة الزمنية المختارة. على الحاسوب الكمي، يمكن حساب كل عنصر مصفوفي بأي خوارزمية تُتيح لنا الحصول على التداخل بين الحالات الكمومية. في هذا الدرس سنركز على اختبار هاداماد. بما أن له بُعد ، فإن الهاميلتوني المُسقَط إلى الفضاء الجزئي سيكون بأبعاد . مع كون صغيراً كفاية (عموماً كافٍ لتحقيق تقارب تقديرات القيم الذاتية)، يمكننا بسهولة قطرنة الهاميلتوني المُسقَط كلاسيكياً. لكننا لا نستطيع قطرنة مباشرةً بسبب عدم تعامد متجهات فضاء كريلوف. سيتعين علينا قياس تداخلاتها وبناء مصفوفة
يُتيح لنا هذا حل مسألة القيم الذاتية في الفضاء غير المتعامد (تُسمى أيضاً مسألة القيم الذاتية المُعممة)
يمكن بعد ذلك الحصول على تقديرات للقيم الذاتية وحالاتها الذاتية لـ بالنظر في حلول مسألة القيم الذاتية المُعممة هذه. فمثلاً، يُحصل على تقدير طاقة الحالة الأساسية بأخذ أصغر قيمة ذاتية ، والحالة الأساسية من متجه القيمة الذاتية المقابل . المعاملات في تُحدد مساهمة المتجهات المختلفة التي تمتد عليها .
مسألة القيم الذاتية المُعممة
لماذا لا يمكننا ببساطة قطرنة ؟ بما أن تحتوي على معلومات حول هندسة أساس كريلوف (الذي يكون غير متعامد في جميع الحالات إلا نادراً)، فإن بمفرده لا يصف إسقاطاً للهاميلتوني الكامل، لذا لا تمت قيمه الذاتية بصلة خاصة لقيم الهاميلتوني الكامل -- إذ يمكن أن تكون قيماً عشوائية. حل مسألة القيم الذاتية المُعممة ضروري للحصول على القيم الذاتية والمتجهات الذاتية التقريبية المقابلة لإسقاط الهاميلتوني الكامل على فضاء كريلوف.
يوضح الشكل تمثيلاً دائرياً لاختبار هاداماد المعدَّل، وهو أسلوب يُستخدم لحساب التداخل بين حالات كمومية مختلفة. لكل عنصر مصفوفي ، يُجرى اختبار هاداماد بين الحالتين و. يُبرز ذلك في الشكل بالترميز اللوني لعناصر المصفوفة وعمليتي و المقابلتين. وبالتالي، يلزم إجراء مجموعة من اختبارات هاداماد لجميع التوليفات الممكنة من متجهات فضاء كريلوف لحساب جميع عناصر مصفوفة الهاميلتوني المُسقَط . السلك العلوي في دائرة اختبار هاداماد هو كيوبت مساعد (ancilla) يُقاس إما في أساس X أو Y، وتُحدد قيمته المتوقعة قيمة التداخل بين الحالتين. السلك السفلي يُمثّل جميع كيوبتات هاميلتوني النظام. تُعدّ عملية إعداداً لكيوبت النظام في الحالة مشروطاً بحالة كيوبت المساعد (وبالمثل لـ )، والعملية تُمثّل تحليل باولي لهاميلتوني النظام . يُعرض تنفيذ هذا على الحاسوب الكمي بمزيد من التفصيل أدناه.
4. قطرنة كريلوف الكمومية على حاسوب كمومي
سننفّذ الآن خوارزمية قطرنة كريلوف الكمومية على حاسوب كمومي حقيقي. لنبدأ باستيراد بعض الحزم المفيدة.
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
نعرّف الدالة أدناه لحل مسألة القيم الذاتية المعممة التي شرحناها للتو.
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
من المفيد في المراحل الأولى من المقارنة أن تعرف الحل الكلاسيكي الدقيق للتحقق من سلوك التقارب. تحسب الدالة أدناه طاقة الحالة الأساسية لهاميلتوني معيّن، مستخدمةً الهاميلتوني وعدد الكيوبتات كمدخلات.
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 الخطوة الأولى: تحويل المسألة إلى دوائر كمومية وعوامل
سنعرّف الآن هاميلتونياً. يختلف هذا عن الدالة السابقة في أن تلك الدالة تأخذ هاميلتونياً كمدخل وتُعيد الحالة الأساسية فقط بطريقة كلاسيكية. أما الهاميلتوني الذي نعرّفه هنا فيحدد مستويات الطاقة لجميع الحالات الذاتية، ويمكن بناؤه باستخدام عوامل باولي وتنفيذه على حاسوب كمومي.
نختار هاميلتونياً يصف سلسلة من الدوارات التي يمكنها الإشارة إلى أي اتجاه في الفضاء، وهو ما يُعرف بـ"سلسلة هايزنبرغ". نفترض أن الدوّار رقم يتأثر بجيرانه الأقرب (الدوّار رقم والدوّار رقم ) دون سواهم. كما نأخذ بعين الاعتبار احتمال اختلاف التفاعل بين الدوارات بحسب المحور الذي تشير إليه. ينشأ هذا التفاوت أحياناً بسبب بنية الشبكة البلورية التي تحتضن تلك الدوارات.
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
يقصر الكود أدناه الهاميلتوني على الحالات أحادية الجسيم، ويستخدم المعيار الطيفي لتحديد حجم مناسب للخطوة الزمنية . نختار بصورة تجريبية قيمةً للخطوة الزمنية dt استناداً إلى حدود عليا لمعيار الهاميلتوني. أظهر المرجع [9] أن خطوة زمنية كافية هي ، وأنه يُفضَّل إلى حدٍّ ما التقليل من تقدير هذه القيمة على التضخيم فيها، إذ إن المبالغة في التقدير تُتيح لمساهمات الحالات عالية الطاقة أن تُفسد حتى الحالة المثلى في فضاء كريلوف. في المقابل، اختيار صغيراً جداً يُضعف التكييف الرياضي لفضاء كريلوف، لأن متجهات الأساس تتشابه أكثر من خطوة إلى أخرى.
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
نحدد عدد خطوات تروتر المستخدمة في التطور الزمني. كما نحدد الحد الأقصى لبُعد كريلوف وهو 4. هذا البُعد ليس كافياً للتطبيقات الواقعية، لكنه كافٍ لهذا المثال. علاوةً على ذلك، سنتحقق من التقارب عند أبعاد أصغر. سنستكشف في دروس لاحقة طرقاً تتيح لنا توسيع نطاق هاميلتونياتنا وإسقاطها على فضاءات فرعية أكبر.
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
تحضير الحالة
اختر حالة مرجعية لها تداخل ما مع الحالة الأساسية. لهذا الهاميلتوني، نستخدم حالةً تحتوي على إثارة في الكيوبت الأوسط كحالتنا المرجعية.
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

التطور الزمني
يمكننا تحقيق عامل التطور الزمني الناتج عن هاميلتوني معيّن: عبر تقريب لي-تروتر. للتبسيط، نستخدم PauliEvolutionGate المدمجة في دائرة التطور الزمني. الصياغة العامة لهذا هي كالتالي.
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
سنستخدم نسخة من هذا أدناه في اختبار هادامار، مع التقدم للأمام بخطوات زمنية .
اختبار هادامار
تذكّر أننا نريد حساب عناصر المصفوفة لكلٍّ من ومصفوفة غرام باستخدام اختبار هادامار. لنراجع كيف يعمل ذلك في هذا السياق، مركّزين أولاً على بناء يُصوَّر الإجراء الكلي بيانياً أدناه. تُذكِّرنا طبقات كتل تحضير الحالة الملونة بأن هذه العملية تُنفَّذ لجميع تركيبات و في فضاءنا الفرعي.
حالات النظام عند الخطوات المشار إليها هي:
هنا هو حدّ باولي في تحليل الهاميلتوني (لاحظ أنه لا يمكن أن يكون تركيباً خطياً من عدة حدود باولي متبادلة التبديل، لأن ذلك لن يكون تآلفياً — التجميع ممكن باستخدام بناء مختلف سنعرضه لاحقاً) ، هي عمليات متحكَّم بها تُحضّر متجهات و من فضاء كريلوف الوحداني، حيث . يُحسب قياس و على هذه الدائرة الجزءَ الحقيقي والجزءَ التخيلي على التوالي من عناصر المصفوفة التي نحتاجها.
انطلاقاً من الخطوة 4 أعلاه، طبّق بوابة هادامار على الكيوبت الصفري.
ثم قِس إما أو .
من التطابق . وبالمثل، يُعطي قياس :
بإضافة هذه الخطوات إلى التطور الزمني الذي أعددناه سابقاً، نكتب ما يلي.
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

نبّهنا من قبل على عمق دوائر تروتر. تنفيذ اختبار هادامار في هذه الظروف قد ينتج دائرةً أعمق بكثير، خاصةً بعد تفكيكها إلى البوابات الأصلية للجهاز. وسيزداد هذا العمق أكثر إذا أخذنا بعين الاعتبار طوبولوجيا الجهاز. لذلك، قبل استهلاك أي وقت على الحاسوب الكمومي، من الحكمة التحقق من عمق العمليات الثنائية الكيوبت في دائرتنا.
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
دائرة بهذا العمق لا يمكنها إنتاج نتائج قابلة للاستخدام على الحواسيب الكمومية الحديثة. إن أردنا بناء و، فنحن بحاجة إلى طريقة أفضل. وهذا هو السبب في تقديم اختبار هادامار الفعّال أدناه.
4. 2 الخطوة 2. تحسين الدوائر والمؤثرات للعتاد المستهدف
اختبار هادامار الكفء
يمكننا تحسين الدوائر العميقة لاختبار هادامار التي حصلنا عليها عن طريق إدخال بعض التقريبات والاعتماد على بعض الافتراضات حول هاميلتوني النموذج. على سبيل المثال، انظر إلى الدائرة التالية لاختبار هادامار:
لنفترض أننا نستطيع حساب كلاسيكياً، وهو القيمة الذاتية لـ تحت الهاميلتوني . هذا الشرط يتحقق عندما يحافظ الهاميلتوني على تماثل U(1). وعلى الرغم من أن هذا قد يبدو افتراضاً قوياً، إلا أن هناك حالات كثيرة يمكن فيها بأمان افتراض وجود حالة خلاء (تُعيَّن في هذه الحالة إلى الحالة ) لا تتأثر بتطبيق الهاميلتوني. هذا ينطبق مثلاً على هاميلتونيات الكيمياء التي تصف جزيئات مستقرة (حيث يُحفظ عدد الإلكترونات). بافتراض أن البوابة تُحضّر الحالة المرجعية المطلوبة ، فمثلاً لإعداد حالة HF في الكيمياء، تكون مجرد حاصل ضرب من بوابات NOT أحادية الكيوبت، وبالتالي تكون المتحكَّم بها مجرد حاصل ضرب من بوابات CNOT. عندئذٍ تُنفّذ الدائرة أعلاه الحالة التالية قبل القياس:
حيث استخدمنا إزاحة الطور القابلة للمحاكاة الكلاسيكية من الخطوة 2 إلى الخطوة 3. وبالتالي، تكون القيم المتوقعة هي
باستخدام هذه الافتراضات، تمكنا من كتابة القيم المتوقعة للمؤثرات المطلوبة بعمليات متحكَّم بها أقل. في الواقع، نحتاج فقط إلى تطبيق إعداد الحالة المتحكَّم به وليس التطورات الزمنية المتحكَّم بها. إن إعادة صياغة حساباتنا كما هو موضح أعلاه ستتيح لنا تقليل عمق الدوائر الناتجة بشكل كبير.
تجدر الإشارة إلى أنه كمكافأة إضافية، بما أن مؤثر باولي يظهر الآن كقياس في نهاية الدائرة بدلاً من كونه بوابة متحكَّم بها في المنتصف، يمكن قياسه جنباً إلى جنب مع مؤثرات باولي الأخرى المتبادلة كما في التحليل المُعطى أعلاه.
تحليل مؤثر التطور الزمني بتحليل تروتر
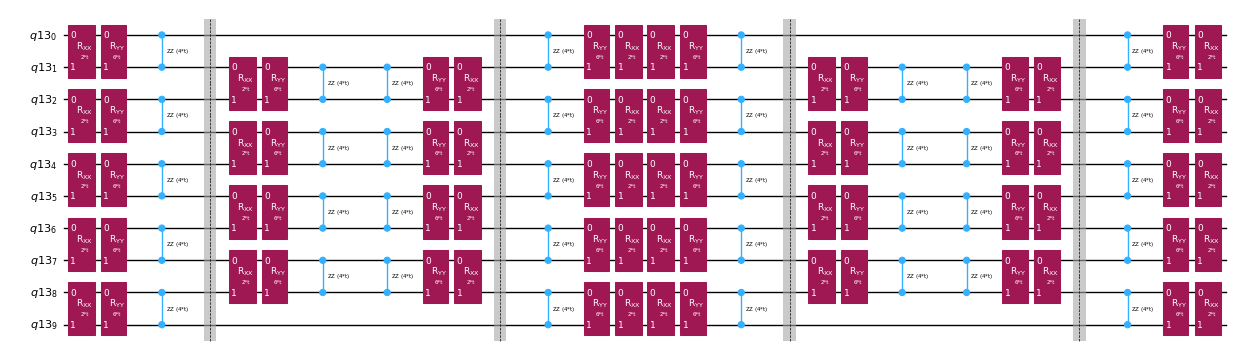
بدلاً من تطبيق مؤثر التطور الزمني بشكل دقيق، يمكننا استخدام تحليل تروتر لتطبيق تقريب له. إن تكرار تحليل تروتر من رتبة معينة عدة مرات يمنحنا تقليلاً إضافياً للخطأ الناتج عن التقريب. في ما يلي، نبني مباشرةً تطبيق تروتر بالطريقة الأكثر كفاءة لرسم التفاعل في الهاميلتوني الذي ندرسه (تفاعلات الجيران الأقرب فقط). عملياً، ندخل دورات باولي ، ، بقوى اقتران ، ، و وزاوية مُعلمَّة والتي تقابل التطبيق التقريبي لـ . نظراً للاختلاف في تعريف دورات باولي والتطور الزمني الذي نحاول تطبيقه، سنضطر إلى استخدام المعامل لتحقيق تطور زمني مقداره . علاوة على ذلك، نعكس ترتيب العمليات لعدد فردي من تكرارات خطوات تروتر، وهو ما يكافئ وظيفياً ولكنه يسمح بدمج العمليات المتجاورة في وحدة واحدة. هذا ينتج دائرة أكثر ضحالة بكثير مما يُحصل عليه باستخدام وظيفة PauliEvolutionGate() العامة.
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
نُعدّ حالة ابتدائية مرة أخرى لاختبار هادامار الكفء هذا.
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

دوائر قالبية لحساب عناصر المصفوفة لـ و عبر اختبار هادامار
الفرق الوحيد بين الدوائر المستخدمة في اختبار هادامار سيكون الطور في مؤثر التطور الزمني والرصيدات المقاسة. لذلك يمكننا إعداد دائرة قالبية تمثل الدائرة العامة لاختبار هادامار، مع عناصر نائبة للبوابات التي تعتمد على مؤثر التطور الزمني.
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
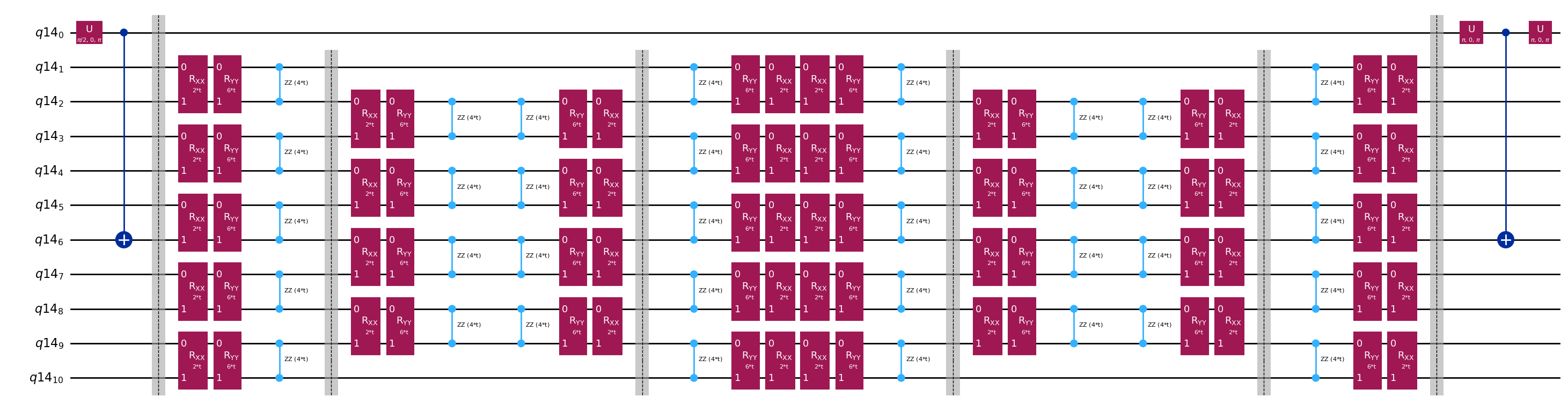
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
هذا العمق أقل بكثير مقارنةً باختبار هادامار الأصلي. وهو عمق قابل للتعامل معه على أجهزة الكمبيوتر الكمومية الحديثة، وإن كان لا يزال مرتفعاً نسبياً. سنحتاج إلى استخدام تقنيات تخفيف الأخطاء الأحدث لنحصل على نتائج مفيدة.
اختر خلفية لتشغيل حساب كريلوف الكمومي عليها، حتى نتمكن من ترجمة دائرتنا للتشغيل على ذلك الكمبيوتر الكمومي.
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
نقوم الآن بترجمة دوائرنا ومؤثراتنا.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

بعد التحسين، انخفض عمق البوابات ثنائية الكيوبت للدائرة المُترجمة بشكل أكبر.
4.3 الخطوة 3. التنفيذ باستخدام بدائية Qiskit Runtime
نُنشئ الآن وحدات PUB للتنفيذ مع Estimator.
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
الدوائر عند قابلة للحساب كلاسيكياً. سننجز هذا قبل الانتقال إلى حالة باستخدام كمبيوتر كمومي.
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
على الرغم من أننا تمكنا من تقليل عمق البوابة بمقادير من الحجم باستخدام اختبار هادامار الكفء، إلا أن العمق لا يزال كافياً ليستلزم تقنيات تخفيف أخطاء متطورة. في ما يلي، نحدد خصائص التخفيف المستخدم. جميع الأساليب المستخدمة مهمة، لكن تجدر الإشارة بشكل خاص إلى تضخيم الأخطاء الاحتمالي (PEA). هذه التقنية القوية تأتي مع قدر كبير من التكلفة الكمومية. الحساب المنجز هنا قد يستغرق 20 دقيقة أو أكثر للتشغيل على كمبيوتر كمومي حقيقي. قد ترغب في تجربة المعاملات أدناه لزيادة الدقة أو تقليلها وما يترتب على ذلك من تكلفة. الإعدادات الافتراضية أدناه تُنتج نتائج عالية الدقة.
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
أخيراً، نُنفّذ الدوائر لـ و مع Estimator.
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 الخطوة 4. المعالجة اللاحقة وتحليل النتائج
ما حصلنا عليه من الحاسوب الكمي هو عناصر المصفوفة الفردية لـ ومجموعات Pauli المتبادلة التبديل التي تُشكّل عناصر مصفوفة . يجب دمج هذه الحدود لاسترداد مصفوفاتنا حتى نتمكن من حل مسألة القيمة الذاتية المعممة.
# Store the outputs as 'results'.
results = job.result()[0]
حساب المؤثر الهاميلتوني الفعّال ومصفوفات التداخل
نحسب أولاً الطور المتراكم بواسطة الحالة أثناء التطور الزمني غير المتحكم به
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
بعد الحصول على نتائج تنفيذ الدوائر، يمكننا معالجة البيانات لاحقاً لحساب عناصر مصفوفة
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
وعناصر مصفوفة
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
وأخيراً، يمكننا حل مسألة القيمة الذاتية المعممة لـ :
والحصول على تقدير لطاقة الحالة الأساسية
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
print("The estimated ground state energy is: ", gnd_en_circ_est)
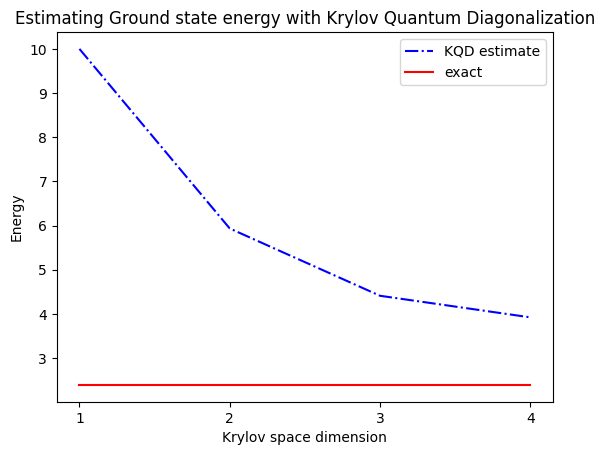
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
بالنسبة لقطاع الجسيم الواحد، يمكننا حساب الحالة الأساسية لهذا القطاع من المؤثر الهاميلتوني بكفاءة كلاسيكياً
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. النقاش والتوسع
للتلخيص، نبدأ بحالة مرجعية، ثم نطوّرها لفترات زمنية مختلفة لتوليد الفضاء الجزئي لكريلوف الوحداني. نسقط مؤثرنا الهاميلتوني على هذا الفضاء الجزئي، ونُقدّر كذلك تداخلات متجهات الفضاء الجزئي، وأخيراً نحل مسألة القيمة الذاتية المعممة ذات الأبعاد الأصغر بصورة كلاسيكية.
لنقارن العوامل التي تحدد التكاليف الحسابية لاستخدام أسلوب كريلوف كلاسيكياً وكمياً. لا توجد تشابهات مثالية بين المقاربتين الكلاسيكية والكمية في كل خطوة. يجمع هذا الجدول بعض معدلات التوسع لخطوات مختلفة للمقارنة.
تذكّر أن المؤثرات الهاميلتونية تحتوي عموماً على حدود لا يمكن قياسها في آنٍ واحد (لأنها لا تتبادل التبديل مع بعضها). نُصنّف حدود المؤثر الهاميلتوني في مجموعات من مؤثرات Pauli المتبادلة التبديل التي يمكن قياسها جميعاً في آنٍ واحد، وقد نحتاج إلى عدد كبير من هذه المجموعات لتغطية جميع الحدود التي لا تتبادل التبديل مع بعضها. يتطلب بناء على حاسوب كمي قياسات منفصلة لكل مجموعة من سلاسل Pauli المتبادلة التبديل في المؤثر الهاميلتوني، وكل منها يتطلب عدداً كبيراً من اللقطات. يجب أن نفعل هذا لـ عنصراً مصفوفياً مختلفاً، تقابل تركيبة من عوامل التطور الزمني المختلفة. توجد أحياناً طرق لتقليص هذا العدد، لكن في هذه المعالجة التقريبية، يتوسع الوقت اللازم لهذا الأمر وفق . يجب تقدير عناصر ، الذي يتوسع وفق . وأخيراً، يستغرق حل مسألة القيمة الذاتية المعممة في الفضاء المُسقَط كلاسيكياً وقتاً يتوسع وفق .
نرى أن قطرنة كريلوف الكمية قد تكون مفيدة في الحالات التي يكون فيها عدد مجموعات Pauli المتبادلة التبديل في المؤثر الهاميلتوني صغيراً نسبياً. تُشير تبعيات التوسع هذه إلى بعض التطبيقات التي يمكن فيها لأسلوب كريلوف أن يكون مفيداً، وإلى أخرى لن يكون فيها كذلك على الأرجح. تمتلك بعض المؤثرات الهاميلتونية تعقيداً عالياً عند ربطها بالكيوبتات، إذ تشمل عدداً كبيراً من سلاسل Pauli غير المتبادلة التبديل التي لا يمكن تقسيمها بسهولة إلى مجموعات قليلة متبادلة التبديل. وهذا صحيح في الغالب في مسائل الكيمياء الكمية مثلاً. يُفرز هذا التعقيد تحديين رئيسيين للحواسيب الكمية قريبة المدى:
- يصبح تقدير كل عنصر من عناصر مكلفاً حسابياً بسبب العدد الكبير من الحدود.
- تصبح دوائر Trotter المطلوبة بالغة العمق بحيث يتعذر تطبيقها عملياً.
كلا النقطتين ستكونان أقل إشكالية حين تصل الحواسيب الكمية إلى مرحلة تحمّل الأخطاء، لكنهما يجب مراعاتهما في المرحلة الراهنة. حتى الأنظمة ذات الربط "الأبسط" مقارنةً بتلك الموجودة في الكيمياء الكمية قد تعاني من نفس العقبات إذا احتوت مؤثراتها الهاميلتونية على عدد كبير جداً من الحدود غير المتبادلة التبديل. أسلوب كريلوف الأكثر فائدة هو الذي يمكن فيه تقسيم المؤثر الهاميلتوني إلى عدد قليل نسبياً من مجموعات Pauli المتبادلة التبديل، وحيث يسهل تطبيق في دوائر Trotter. كلا الشرطين يتحققان مثلاً في كثير من نماذج الشبكة ذات الاهتمام في الفيزياء. تكون KQD مفيدة بشكل خاص حين تكون المعرفة بالحالة الأساسية شحيحة جداً. ويعود ذلك إلى ضمانات التقارب الجوهرية وإمكانية تطبيقها في الحالات التي تكون فيها الأساليب البديلة غير قابلة للاستخدام بسبب المعرفة المحدودة بالحالة الأساسية.
على الرغم من أن KQD أداة قوية، إلا أن جوانبها المستهلكة للوقت، ولا سيما تقدير كل عنصر من عناصر المؤثر الهاميلتوني المُسقَط وتداخل حالات كريلوف، تمثّل فرصاً للتحسين. يتمثل أحد الأساليب البديلة في الاستفادة من أساليب كريلوف بالتزامن مع الأساليب القائمة على أخذ العينات، وهو موضوع الدرس التالي.
6. الملاحق
الملحق الأول: فضاء كريلوف الجزئي من التطورات الزمنية الحقيقية
يُعرَّف فضاء كريلوف الوحداني على النحو الآتي
لخطوة زمنية سنحددها لاحقاً. لنفترض مؤقتاً أن زوجي: نعرّف حينئذٍ . لاحظ أنه حين نسقط المؤثر الهاميلتوني على فضاء كريلوف أعلاه، لا يمكن تمييزه عن فضاء كريلوف
أي حين تُزاح جميع التطورات الزمنية للخلف بمقدار خطوات زمنية. السبب في عدم إمكانية التمييز هو أن عناصر المصفوفة
ثابتة تحت الإزاحات الكلية لزمن التطور، إذ إن التطورات الزمنية تتبادل التبديل مع المؤثر الهاميلتوني. أما للـ الفردي، فيمكننا استخدام التحليل الخاص بـ .
نريد أن نُثبت أن ثمة حالة ذات طاقة منخفضة مضمونة الوجود في مكان ما من فضاء كريلوف هذا. نفعل ذلك بالاستناد إلى النتيجة التالية، المستنبطة من المبرهنة 3.1 في [3]:
الادعاء 1: توجد دالة بحيث تكون الطاقات ضمن النطاق الطيفي للمؤثر الهاميلتوني (أي بين طاقة الحالة الأساسية والطاقة القصوى)...
- لجميع قيم التي تبعد عن ، أي أنها تتناقص أسياً
- هي تركيبة خطية من لـ
نُقدّم برهاناً في الأسفل، لكن يمكن تجاوزه بأمان ما لم يكن المرء يريد فهم الحجة الرياضية الكاملة الصارمة. نُركّز الآن على الدلالات المترتبة على الادعاء أعلاه. من الخاصية 3 أعلاه، يتضح أن فضاء كريلوف المُزاح أعلاه يحتوي على الحالة . هذه هي حالتنا ذات الطاقة المنخفضة. لنتأكد من ذلك، نكتب في أساس القيم الذاتية للطاقة:
حيث هي الحالة الذاتية الطاقوية k وأمبليتودها في الحالة الابتدائية هي . معبَّراً عن هذا، تكون على النحو
مستخدمين حقيقة أننا يمكننا استبدال بـ حين يؤثر على الحالة الذاتية . خطأ الطاقة لهذه الحالة هو إذن
لتحويل هذا إلى حدٍّ أعلى أيسر فهماً، نُفصل أولاً مجموع البسط إلى حدود حيث وحدود حيث :
يمكننا تحديد الحد الأعلى للحد الأول بـ ،
حيث تنبثق الخطوة الأولى من أن لكل في المجموع، وتنبثق الخطوة الثانية من أن المجموع في البسط هو جزء من المجموع في المقام. أما للحد الثاني، فنحدد أولاً حداً أدنى للمقام بـ ، إذ إن : وبجمع كل شيء معاً، يعطينا ذلك
لتبسيط ما تبقى، لاحظ أنه لجميع هذه القيم ، من تعريف نعلم أن . إضافةً إلى تحديد الحد الأعلى لـ وتحديد الحد الأعلى لـ ، نحصل على
يصح هذا لأي ، لذا إذا ضبطنا مساوياً لخطأ هدفنا، فإن حد الخطأ أعلاه يتقارب نحوه أسياً مع بُعد كريلوف . لاحظ أيضاً أنه إذا كان فإن الحد يختفي كلياً من الحد أعلاه.
لاستكمال الحجة، نلاحظ أولاً أن ما سبق هو مجرد خطأ الطاقة للحالة المحددة ، لا خطأ الطاقة للحالة الأدنى طاقةً في فضاء كريلوف. غير أنه وفق المبدأ المتغيري (Rayleigh-Ritz)، فإن خطأ الطاقة للحالة الأدنى طاقةً في فضاء كريلوف يكون محدوداً من الأعلى بخطأ الطاقة لأي حالة في فضاء كريلوف، لذا فإن ما سبق هو أيضاً حد أعلى لخطأ الطاقة للحالة الأدنى طاقةً، أي ناتج خوارزمية قطرنة كريلوف الكمية.
يمكن إجراء تحليل مشابه للسابق يأخذ في الحسبان الضوضاء وإجراء العتبة المُناقَش في الدفتر. راجع [2] و[4] لهذا التحليل.
الملحق الثاني: برهان الادعاء 1
ما يلي مستنبط في معظمه من [3]، المبرهنة 3.1: ليكن وليكن فضاء كثيرات الحدود المتبقية (كثيرات الحدود التي تكون قيمتها عند 0 تساوي 1) من الدرجة على الأكثر . حل
هو
والقيمة الدنيا المقابلة هي
نريد تحويل هذا إلى دالة يمكن التعبير عنها بطريقة طبيعية باستخدام الأسيات المركبة، لأن تلك هي التطورات الزمنية الحقيقية التي تُولّد فضاء كريلوف الكمي. للقيام بذلك، من المفيد تقديم التحويل التالي للطاقات ضمن النطاق الطيفي للمؤثر الهاميلتوني إلى أعداد في النطاق : نعرّف
حيث خطوة زمنية بحيث . لاحظ أن وأن تنمو كلما ابتعدت عن .
الآن باستخدام كثيرة الحدود مع المعاملات a وb وd المضبوطة على و و d = int(r/2)، نعرّف الدالة:
حيث هي طاقة الحالة الأساسية. يمكننا التحقق بإدراج أن هي كثيرة حدود مثلثية من الدرجة ، أي تركيبة خطية من لـ . علاوةً على ذلك، من تعريف أعلاه لدينا أن ولأي ضمن النطاق الطيفي بحيث لدينا
المراجع:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).