خوارزمية التباين الكمي لإيجاد القيمة الذاتية الصغرى (VQE)
ستُعرِّفك هذه الدرس بخوارزمية التباين الكمي لإيجاد القيمة الذاتية الصغرى، وستشرح أهميتها بوصفها خوارزميةً أساسيةً في الحوسبة الكمية، وستستعرض نقاط قوّتها وضعفها. لن تكون VQE وحدها، دون أساليب مساعِدة، كافيةً على الأرجح للحسابات الكمية الحديثة على نطاق المنفعة العملية. ومع ذلك، تظلّ مهمّةً كنموذج أصيل للأساليب الهجينة الكلاسيكية-الكمية، وأساسٍ جوهري تبنى عليه كثير من الخوارزميات الأكثر تقدّمًا.
يُقدّم هذا الفيديو نظرةً عامة على VQE والعوامل المؤثّرة في كفاءتها. يُضيف النص أدناه مزيدًا من التفاصيل ويُطبّق VQE باستخدام Qiskit.
1. ما هي VQE؟
خوارزمية VQE هي خوارزمية تستخدم الحوسبة الكلاسيكية والكمية معًا لإنجاز مهمّة محدّدة. تتكوّن عملية حساب VQE من أربعة مكوّنات رئيسية:
- عامل (مؤثّر): غالبًا ما يكون هاميلتونيًا نُسمّيه ، يصف خاصيةً في نظامك تريد تحسينها. بعبارة أخرى، أنت تبحث عن المتّجه الذاتي لهذا العامل الذي يقابل أصغر قيمة ذاتية. كثيرًا ما نُسمّي هذا المتّجه الذاتي "الحالة الأساسية".
- "نموذج أوّلي" (ansatz) (كلمة ألمانية تعني "مقاربة"): هو دائرة كمية تُهيّئ حالةً كميةً تُقارب المتّجه الذاتي الذي تبحث عنه. في الحقيقة، النموذج الأوّلي هو عائلة من الدوائر الكمية، لأن بعض البوّابات فيه ذات معاملات متغيّرة يمكن تعديلها. تستطيع هذه العائلة من الدوائر تهيئة عائلة من الحالات الكمية التي تُقارب الحالة الأساسية.
- Estimator: وسيلة لتقدير قيمة التوقّع للعامل في الحالة الكمية التباينية الحالية . أحيانًا يكون ما يهمّنا فعلًا هو قيمة التوقّع هذه فقط، وهو ما نُسمّيه دالة التكلفة. وأحيانًا نهتمّ بدالة أكثر تعقيدًا يمكن كتابتها انطلاقًا من قيمة توقّع واحدة أو أكثر.
- مُحسِّن كلاسيكي: خوارزمية تُغيّر المعاملات محاولةً تصغير دالة التكلفة.
لننظر في كلٍّ من هذه المكوّنات بمزيد من العمق.
1.1 العامل (الهاميلتوني)
في صميم مسألة VQE يكمن عامل يصف نظامًا موضع الاهتمام. نفترض هنا أن أصغر قيمة ذاتية والمتّجه الذاتي المقابل لهذا العامل مفيدان لغرض علمي أو تجاري ما. قد تشمل الأمثلة هاميلتونيًا كيميائيًا يصف جزيئًا، بحيث تقابل أصغر قيمة ذاتية للعامل طاقة الحالة الأساسية للجزيء، ويصف المتّجه الذاتي المقابل هندسة الجزيء أو توزيع الإلكترونات فيه. أو قد يصف العامل تكلفة عملية معيّنة يُراد تحسينها، وتقابل المتّجهات الذاتية مسارات أو ممارسات معيّنة. في بعض المجالات كالفيزياء، يشير "الهاميلتوني" تقريبًا دائمًا إلى عامل يصف طاقة نظام فيزيائي. أما في الحوسبة الكمية، فمن الشائع أن يُشار إلى العوامل الكمية التي تصف مسائل تجارية أو لوجستية أيضًا باسم "هاميلتوني". سنتبنّى هذا الاصطلاح هنا.

تحويل المسألة الفيزيائية أو مسألة التحسين إلى كيوبتات هو مهمّة غير تافهة في العادة، لكن تفاصيل ذلك ليست محور هذه الدورة. يمكن إيجاد نقاش عام حول تحويل المسألة إلى عامل كمي في الحوسبة الكمية في التطبيق. أما نظرة أعمق على تحويل مسائل الكيمياء إلى عوامل كمية فستجدها في الكيمياء الكمية مع VQE.
لأغراض هذه الدورة، سنفترض أن شكل الهاميلتوني معروف. على سبيل المثال، هاميلتوني جزيء الهيدروجين البسيط (في ظلّ افتراضات معيّنة للفضاء النشط، وباستخدام محوّل Jordan-Wigner) هو:
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy
from qiskit.quantum_info import SparsePauliOp
hamiltonian = SparsePauliOp(
[
"IIII",
"IIIZ",
"IZII",
"IIZI",
"ZIII",
"IZIZ",
"IIZZ",
"ZIIZ",
"IZZI",
"ZZII",
"ZIZI",
"YYYY",
"XXYY",
"YYXX",
"XXXX",
],
coeffs=[
-0.09820182 + 0.0j,
-0.1740751 + 0.0j,
-0.1740751 + 0.0j,
0.2242933 + 0.0j,
0.2242933 + 0.0j,
0.16891402 + 0.0j,
0.1210099 + 0.0j,
0.16631441 + 0.0j,
0.16631441 + 0.0j,
0.1210099 + 0.0j,
0.17504456 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
],
)
لاحظ أن الهاميلتوني أعلاه يحتوي على حدود مثل ZZII وYYYY لا تتبادل مع بعضها. أي أنه لقياس ZZII، نحتاج إلى قياس عامل باولي Z على الكيوبت 3 (من بين قياسات أخرى). لكن لقياس YYYY، نحتاج إلى قياس عامل باولي Y على الكيوبت 3 ذاته. توجد علاقة عدم يقين بين عاملَي Y و Z على الكيوبت نفسه؛ لا يمكننا قياس كليهما في الوقت ذاته. سنعود إلى هذه النقطة لاحقًا وعبر الدورة بأكملها.
الهاميلتوني أعلاه هو عامل مصفوفة . قطرنة العامل لإيجاد أصغر قيمة ذاتية طاقوية لا يُعدّ أمرًا صعبًا.
import numpy as np
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues), "hartrees")
The ground state energy is -1.1459778447627311 hartrees
المحلّلات الكلاسيكية للقيم الذاتية بالقوة الغاشمة لا يمكنها التوسّع لوصف طاقات أو أشكال هندسية لأنظمة ضخمة من الذرّات كالأدوية أو البروتينات. VQE هي إحدى المحاولات الأولى لتوظيف الحوسبة الكمية في هذه المسألة.
سنتعامل في هذا الدرس مع هاميلتونيات أضخم بكثير مما سبق. لكن سيكون مضيعةً للوقت دفع VQE إلى حدودها القصوى قبل أن نُقدّم بعض الأدوات الأكثر تقدّمًا التي يمكنها تعزيز VQE أو استبدالها، لاحقًا في هذه الدورة.
1.2 النموذج الأوّلي (Ansatz)
كلمة "ansatz" ألمانية تعني "مقاربة". الجمع الصحيح بالألمانية هو "ansätze"، وإن كان كثيرًا ما يُرى أيضًا "ansatzes" أو "ansatze". في سياق VQE، النموذج الأوّلي هو الدائرة الكمية التي تستخدمها لإنشاء دالة موجية متعدّدة الكيوبتات تُقارب الحالة الأساسية للنظام الذي تدرسه، وتُنتج بذلك أصغر قيمة توقّع ممكنة للعامل. ستحتوي هذه الدائرة الكمية على معاملات تباينية (تُجمَع في العادة في متّجه المتغيّرات ).

يُختار مجموعة أولية من القيم للمعاملات التباينية. سنُسمّي العملية التوحيدية للنموذج الأوّلي على الدائرة . بشكل افتراضي، تُهيَّأ جميع الكيوبتات في أجهزة IBM® الكمية على الحالة . عند تشغيل الدائرة، سيكون وضع الكيوبتات:
لو كنّا بحاجة فقط إلى أدنى طاقة (بلغة الأنظمة الفيزيائية)، كان يكفي تقديرها بقياس الطاقة مرات كثيرة وأخذ أدناها. لكننا في العادة نريد أيضًا التهيّؤ الذي يُعطي أدنى طاقة أو قيمة ذاتية. لذا فالخطوة التالية هي تقدير قيمة التوقّع للهاميلتوني، وهو ما يتمّ عبر القياسات الكمية. يتضمّن ذلك كثيرًا من التفاصيل. لكن يمكننا فهم هذه العملية بشكل نوعي بالإشارة إلى أن الاحتمال لقياس طاقة (مجددًا بلغة الأنظمة الفيزيائية) مرتبط بقيمة التوقّع بالصيغة:
الاحتمال مرتبط أيضًا بالتداخل بين الحالة الذاتية والحالة الراهنة للنظام :
لذا بإجراء قياسات كثيرة لعوامل باولي المكوِّنة لهاميلتونينا، نستطيع تقدير قيمة التوقّع للهاميلتوني في الحالة الراهنة للنظام . الخطوة التالية هي تغيير المعاملات ومحاولة الاقتراب أكثر من الحالة الأساسية (الأدنى طاقةً) للنظام. بسبب المعاملات التباينية في النموذج الأوّلي، يُشار إليه أحيانًا بـ الشكل التباينيّ.
قبل الانتقال إلى عملية التباين، لاحظ أنه كثيرًا ما يكون من المفيد أن تبدأ حالتك من حالة "تخمين جيّد". ربّما تعرف ما يكفي عن نظامك لاختيار تخمين ابتدائي أفضل من . على سبيل المثال، من الشائع في التطبيقات الكيميائية تهيئة الكيوبتات على حالة Hartree-Fock. هذا التخمين الابتدائي الذي لا يحتوي على معاملات تباينية يُسمّى الحالة المرجعية. لنُسمِّ الدائرة الكمية المستخدمة لإنشاء الحالة المرجعية . كلّما أصبح من المهمّ التمييز بين الحالة المرجعية وبقية النموذج الأوّلي، نستخدم: أو بشكل مكافئ:
1.3 المُقدِّر
نحتاج إلى طريقة لتقدير قيمة التوقّع للهاميلتوني في حالة تباينية معيّنة . لو كان بالإمكان قياس العامل كاملًا مباشرةً، لكان الأمر بسيطًا: نُجري قياسات كثيرة (لنقل ) ونحسب متوسّطها:
هنا، رمز يُذكّرنا أن قيمة التوقّع هذه لن تكون دقيقة تمامًا إلا في الحدّ عندما . لكن مع آلاف القياسات على دائرة، يكون خطأ أخذ العيّنات في قيمة التوقّع منخفضًا نسبيًا. ثمّة اعتبارات أخرى كالضوضاء تصبح مشكلة في الحسابات شديدة الدقة.
غير أنه في العموم لا يمكن قياس دفعةً واحدة. فقد يحتوي على عوامل باولي X و Y و Z متعدّدة لا تتبادل مع بعضها. لذلك يجب تفكيك الهاميلتوني إلى مجموعات من العوامل القابلة للقياس في آنٍ واحد، وتقدير كلّ مجموعة منفردةً، ثمّ جمع النتائج للحصول على قيمة التوقّع. سنعود إلى هذا بمزيد من التفصيل في الدرس القادم عند مناقشة التوسّع في الأساليب الكلاسيكية والكمية. هذا التعقيد في القياس هو أحد الأسباب التي تجعلنا بحاجة إلى كود فائق الكفاءة لتنفيذ عملية التقدير هذه. في هذا الدرس وما بعده، سنستخدم لهذا الغرض الأداة البدائية Estimator في Qiskit Runtime.
1.4 المُحسِّنات الكلاسيكية
المُحسِّن الكلاسيكي هو أي خوارزمية كلاسيكية مُصمَّمة لإيجاد النقاط القصوى لدالة مستهدفة (وعادةً ما تكون نقطة صغرى). تبحث هذه الخوارزميات في فضاء المعاملات الممكنة عن مجموعة تُصغّر دالةً محدّدة. يمكن تصنيفها على نطاق واسع إلى طرق تعتمد على التدرّج (gradient-based) التي تستخدم معلومات التدرّج، وطرق لا تعتمد على التدرّج (gradient-free) التي تعمل كمُحسِّنات ذات صندوق أسود. يمكن لاختيار المُحسِّن الكلاسيكي أن يؤثّر تأثيرًا كبيرًا على أداء الخوارزمية، لا سيّما في وجود الضوضاء في الأجهزة الكمية. تشمل المُحسِّنات الشائعة في هذا المجال Adam و AMSGrad و SPSA التي أثبتت نتائج واعدة في البيئات الضوضائية. ومن المُحسِّنات الأكثر تقليديةً COBYLA و SLSQP.
سير العمل الشائع (الموضَّح في القسم 3.3) هو استخدام إحدى هذه الخوارزميات كطريقة داخل دالة تصغير مثل دالة minimize في scipy. تأخذ هذه الدالة كوسيطات:
- دالةً يُراد تصغيرها. غالبًا ما تكون قيمة التوقّع للطاقة. لكنها يُشار إليها عمومًا بـ"دوال التكلفة".
- مجموعةً من المعاملات لبدء البحث منها. كثيرًا ما تُسمّى أو .
- وسيطاتٍ تشمل وسيطات دالة التكلفة. في الحوسبة الكمية مع Qiskit، ستشمل هذه الوسيطات النموذجَ الأوّلي والهاميلتونيَّ والأداة البدائية Estimator primitive التي سيُناقَش أكثر في القسم التالي.
- "طريقة" تصغير. تُشير إلى الخوارزمية المحدّدة المستخدمة للبحث في فضاء المعاملات. هنا نُحدّد، مثلًا، COBYLA أو SLSQP.
- خياراتٍ. قد تختلف الخيارات المتاحة من طريقة لأخرى. لكن مثالًا تشترك فيه تقريبًا جميع الطرق هو الحدّ الأقصى لعدد تكرارات المُحسِّن قبل إنهاء البحث: 'maxiter'.

في كلّ خطوة تكرارية، يُقدَّر قيمة التوقّع للهاميلتوني بإجراء قياسات كثيرة. تُعيد دالة التكلفة هذه الطاقة المُقدَّرة، ويُحدِّث المُصغِّر معلوماته عن مشهد الطاقة. ما يفعله المُحسِّن بالضبط لاختيار الخطوة التالية يتفاوت من طريقة لأخرى. بعضها يستخدم التدرّجات ويختار اتجاه أشدّ انحدار. وقد يأخذ بعضها الضوضاء بعين الاعتبار وقد يشترط أن تنخفض التكلفة بهامش كبير قبل قبول أن الطاقة الحقيقية تنخفض في ذلك الاتجاه.
# Example syntax for minimization
# from scipy.optimize import minimize
# res = minimize(cost_func, x0, args=(ansatz, hamiltonian, estimator), method="cobyla",
# options={'maxiter': 200})
1.5 مبدأ التباين
مبدأ التباين في هذا السياق في غاية الأهمية؛ إذ ينصّ على أن أيّ دالة موجية تباينية لا يمكنها أن تُعطي قيمة توقّع للطاقة (أو التكلفة) أدنى مما تُعطيه دالة موجية الحالة الأساسية. رياضيًا:
يسهل التحقّق من هذا إذا لاحظنا أن مجموعة كلّ الحالات الذاتية للعامل تُشكّل أساسًا كاملًا لفضاء هيلبرت. بمعنى آخر، يمكن كتابة أيّ حالة وبالخصوص كمجموع موزون (منظَّم) من هذه الحالات الذاتية لـ:
حيث ثوابت يُراد تحديدها، و. نترك هذا كتمرين للقارئ. لكن لاحظ التداعي: الحالة التباينية التي تُنتج أدنى قيمة توقّع للطاقة هي أفضل تقدير للحالة الأساسية الحقيقية.
اختبر فهمك
تحقّق رياضيًا من أن لأيّ حالة تباينية .
Answer
باستخدام التوسيع المُعطى للحالة التباينية بدلالة الحالات الذاتية للطاقة،
نستطيع كتابة قيمة التوقّع للطاقة التباينية على النحو التالي:
لجميع المعاملات . لذا نستطيع كتابة:
2. المقارنة مع سير العمل الكلاسيكي
لنفترض أننا مهتمّون بمصفوفة ذات N صفًا و N عمودًا. افترض أن مصفوفتك ضخمة جدًا لدرجة أن القطرنة الدقيقة ليس خيارًا مطروحًا. افترض كذلك أنك تعرف ما يكفي عن مسألتك لتخمين الهيكل العام للحالة الذاتية المستهدفة، وتريد استكشاف حالات مشابهة لتخمينك الأوّلي لترى إن كان بالإمكان خفض التكلفة/الطاقة أكثر. هذا هو الأسلوب التباينيّ، وهو إحدى الطرق المستخدمة حين لا يكون القطرنة الدقيقة ممكنًا.
2.1 سير العمل الكلاسيكي
باستخدام حاسوب كلاسيكي، سيجري الأمر على النحو التالي:
- اختر حالةً تخمينيةً بمعاملات ستُغيّرها: . وإن كان هذا التخمين الأوّلي يمكن أن يكون عشوائيًا، إلا أن ذلك غير مُستحسَن. نريد توظيف معرفتنا بالمسألة لتفصيل تخميننا قدر الإمكان.
- احسب قيمة التوقّع للعامل والنظام في تلك الحالة:
- غيّر المعاملات التباينية وكرّر: .
- استخدم المعلومات المتراكمة حول مشهد الحالات الممكنة في فضاءك التباينيّ لتحسين تخمينات أفضل فأفضل والاقتراب من الحالة المستهدفة. مبدأ التباين يضمن أن حالتنا التباينية لا يمكنها أن تُعطي قيمة ذاتية أدنى من قيمة الحالة الأساسية المستهدفة. لذا كلّما انخفضت قيمة التوقّع، كان تقريبنا للحالة الأساسية أفضل:
لنتأمّل صعوبة كلّ خطوة في هذا الأسلوب. ضبط المعاملات أو تحديثها أمر يسير حسابيًا؛ الصعوبة هناك في اختيار معاملات ابتدائية مفيدة مُلهَمة بالفيزياء. استخدام المعلومات المتراكمة من التكرارات السابقة لتحديث المعاملات بطريقة تُقرّبك من الحالة الأساسية ليس أمرًا تافهًا. لكن توجد خوارزميات تحسين كلاسيكية تؤدّي ذلك بكفاءة عالية. هذا التحسين الكلاسيكي مكلف فقط لأنه قد يحتاج إلى تكرارات كثيرة؛ في أسوأ الحالات، قد يتوسّع عدد التكرارات توسّعًا أسّيًا مع N. الخطوة الأكثر تكلفةً حسابيًا بالتأكيد تقريبًا هي حساب قيمة التوقّع للمصفوفة في حالة معطاة :
يجب أن تعمل المصفوفة على المتّجه ذي العناصر N، وهو ما يقابل: عملية ضرب في أسوأ الحالات. يجب إجراء ذلك عند كلّ تكرار للمعاملات. للمصفوفات الضخمة للغاية، يكون هذا ذا تكلفة حسابية عالية.
2.2 سير العمل الكمي ومجموعات باولي المتبادلة
الآن تخيّل إسناد هذا الجزء من الحساب إلى حاسوب كمي. بدلًا من حساب قيمة التوقّع، تُقدِّرها بتهيئة الحالة على الحاسوب الكمي باستخدام نموذجك الأوّلي التباينيّ، ثمّ إجراء القياسات.
قد يبدو هذا أسهل مما هو عليه فعليًا. في العموم ليس سهل القياس. فقد يتكوّن من عوامل باولي X و Y و Z متعدّدة لا تتبادل مع بعضها. لكن يمكن كتابة على شكل تركيب خطّي لحدود كلٌّ منها قابل للقياس بسهولة (مثل عوامل باولي أو مجموعات عوامل باولي المتبادلة كيوبيتًا بكيوبت). قيمة التوقّع للعامل في حالة ما هي إلا المجموع الموزون لقيم توقّع الحدود المكوِّنة . هذه الصيغة تصحّ لأيّ حالة ، لكنّنا سنستخدمها تحديدًا مع حالاتنا التباينية .
حيث سلسلة باولي مثل IZZX…XIYX، أو عدة سلاسل من هذا القبيل تتبادل مع بعضها. إذن وصف قيمة التوقّع الذي يتوافق أكثر مع واقع القياس على الحواسيب الكمية هو:
وفي سياق دالتنا الموجية التباينية:
يمكن قياس كلّ حدٍّ من الحدود عدد من المرات للحصول على عيّنات القياس حيث ، مما يُعطي قيمة توقّع وانحرافًا معياريًا . نستطيع جمع هذه الحدود ونشر الأخطاء عبر المجموع للحصول على قيمة توقّع إجمالية وانحراف معياري .
لا يتطلّب هذا ضربًا واسع النطاق، ولا أيّ عملية تتوسّع بالضرورة مثل . بدلًا من ذلك يتطلّب قياسات متعدّدة على الحاسوب الكمي. إن لم تكن بحاجة إلى عدد كبير منها، فقد يكون هذا الأسلوب فعّالًا. وهذا هو الجزء الكمي من VQE.
لكن دعنا نتحدّث عن الأسباب التي قد تجعل هذا غير فعّال. سبب أوّل لكثرة القياسات هو تقليل عدم اليقين الإحصائي في تقديراتك، لإجراء حسابات عالية الدقة جدًا. سبب آخر هو عدد سلاسل باولي اللازمة لتغطية مصفوفتك بأكملها. ولأن مصفوفات باولي (مع الهوية: X و Y و Z و I) تُفرِّق الفضاء على جميع عوامل ذات بُعد معيّن، فمن المضمون أن نستطيع كتابة مصفوفتنا موضع الاهتمام كمجموع موزون لعوامل باولي، كما فعلنا من قبل.
حيث سلسلة باولي تعمل على جميع الكيوبتات التي تصف نظامك مثل IZZX…XIYX، أو عدة سلاسل متبادلة. تذكّر أن Qiskit يستخدم ترميز النهاية الصغيرة (little endian)، حيث يعمل عامل باولي رقم من اليمين على الكيوبت رقم . إذن يمكننا قياس عاملنا بقياس سلسلة من عوامل باولي.
لكن لا يمكننا قياس كلّ هذه العوامل في آنٍ واحد. عوامل باولي (باستثناء I) لا تتبادل مع بعضها إن ارتبطت بالكيوبت ذاته. مثلًا، يمكننا قياس IZIZ وZZXZ في آنٍ واحد، لأننا نستطيع قياس I و Z في الوقت ذاته للكيوبت الثالث، ونستطيع معرفة I و X في الوقت ذاته للكيوبت الأوّل. لكن لا يمكننا قياس ZZZZ وZZZX في آنٍ واحد، لأن Z و X لا يتبادلان، وكلاهما يعمل على الكيوبت 0. قد يتذكّر القرّاء ذوو الخبرة أن مجموعتَين من عوامل باولي قد تتبادلان كمجموعة حتى وإن كانت قياسات كلّ كيوبت منفردٍ لا تتبادل. تفترض Estimator قياسات باولي بالضرب التنسوري (عبر تدويرات الأساس)، وهو ما يقابل تجميع العوامل المتبادلة كيوبتًا بكيوبت. لذا لتقدير سلسلتَين (A و B) من عوامل باولي في آنٍ واحد باستخدام Estimator، يجب أن تتبادل عوامل باولي لكلّ كيوبت في A و B. وهذا يعني أيضًا أننا لا نستطيع قياس ZZZZ وZZXX في آنٍ واحد.

إذن نُفكّك مصفوفتنا إلى مجموع من عوامل باولي تعمل على كيوبتات مختلفة. بعض عناصر هذا المجموع يمكن قياسها دفعةً واحدة؛ نُسمّي هذا مجموعة من باولي المتبادلة. وتبعًا لعدد الحدود غير المتبادلة، قد نحتاج إلى كثير من هذه المجموعات. لنُسمِّ عدد مجموعات سلاسل باولي المتبادلة . إن كان صغيرًا، فقد يعمل هذا بشكل جيّد. أما إن كانت لـ ملايين من المجموعات، فلن يكون مفيدًا.
العمليات اللازمة لتقدير قيمة التوقّع مجمَّعة في الأداة البدائية لـQiskit Runtime المُسمّاة Estimator. لمعرفة المزيد عن Estimator، راجع مرجع API في توثيق IBM Quantum®. يمكن استخدام Estimator مباشرةً، لكن Estimator تُعيد أكثر بكثير من مجرّد أصغر قيمة ذاتية للطاقة. فهي تُعيد أيضًا معلومات حول الخطأ المعياري للتجميع. لذا في سياق مسائل التصغير، يُرى Estimator كثيرًا داخل دالة تكلفة. لمعرفة المزيد عن مدخلات Estimator ومخرجاتها، راجع هذا الدليل في توثيق IBM Quantum.
تُسجّل قيمة التوقّع (أو دالة التكلفة) لمجموعة المعاملات المستخدمة في حالتك، ثمّ تُحدِّث المعاملات. بمرور الوقت، يمكنك استخدام قيم التوقّع أو قيم دالة التكلفة التي قدّرتها لتقريب تدرّج دالة التكلفة في الفضاء الجزئي من الحالات التي يأخذ عيّنات منها نموذجك الأوّلي. يوجد كلا نوعَي المُحسِّنات الكلاسيكية: المعتمِدة على التدرّج وغير المعتمِدة عليه. وكلاهما يعاني من مشكلات محتملة في قابلية التدريب، كالحدود الصغرى المحلية المتعدّدة، والمناطق الواسعة في فضاء المعاملات التي يكاد تدرّجها يكون صفرًا، وتُسمّى الهضاب القاحلة.

2.3 العوامل التي تحدّد التكلفة الحسابية
VQE لن تحلّ أصعب مسائل الكيمياء الكمية لديك. لا. لكن التفوّق في جميع الحسابات ليس الهدف. لقد غيّرنا ما يحدّد التكلفة الحسابية.

انتقلنا من عملية تعتمد تعقيدها فقط على بُعد المصفوفة إلى عملية تعتمد على الدقة المطلوبة وعدد عوامل باولي غير المتبادلة المكوِّنة للمصفوفة. هذا الأخير ليس له نظير في الحوسبة الكلاسيكية.
بناءً على هذه الاعتماديات، قد يكون هذا الأسلوب مفيدًا للمصفوفات المتفرّقة أو المصفوفات التي تنطوي على عدد قليل من سلاسل باولي غير المتبادلة. هذا هو الحال بالنسبة لأنظمة الأسبينات المتفاعلة، مثلًا. أما للمصفوفات الكثيفة، فقد يكون أقلّ فائدةً. نعرف على سبيل المثال أن الأنظمة الكيميائية كثيرًا ما تمتلك هاميلتونيات تنطوي على مئات أو آلاف بل ملايين من سلاسل باولي. ثمّة أعمال مثيرة للاهتمام تمّت لتقليل عدد هذه الحدود. لكن الأنظمة الكيميائية قد تكون أنسب لبعض الخوارزميات الأخرى التي سنناقشها في هذه الدورة.
اختبر فهمك
ضع في اعتبارك هاميلتونيًا على أربعة كيوبتات يحتوي على الحدود التالية:
IIXX، IIXZ، IIZZ، IZXZ، IXXZ، ZZXZ، XZXZ، ZIXZ، ZZZZ، XXXX
تريد تصنيف هذه الحدود في مجموعات بحيث يمكن قياس جميع الحدود في كلّ مجموعة في آنٍ واحد. ما هو أقلّ عدد من المجموعات يمكنك تشكيله بحيث تُغطّي جميع الحدود؟
Answer
يمكن القيام بذلك في 4 مجموعات. لاحظ أن هذه الحلول ليست فريدة في العادة.
IIXX، XXXX، IIZZ، ZZZZ
IIXZ، IZXZ، ZIXZ، ZZXZ
IXXZ
XZXZ
ما الذي تتوقّع أنه يُصعّب الكيمياء الكمية مع VQE عادةً: عدد الحدود في الهاميلتوني، أم إيجاد نموذج أوّلي جيّد؟
Answer
اتّضح أن ثمّة نماذج أوّلية مُحسَّنة جدًا للسياقات الكيميائية. عدد الحدود في الهاميلتوني، ومن ثمّ عدد القياسات المطلوبة، هو ما يُسبّب مشكلات أكثر في العادة.
3. مثال على هاميلتوني
لنطبّق هذه الخوارزمية عمليًا باستخدام مصفوفة هاميلتوني صغيرة حتى نرى ما يجري في كلّ خطوة. سنستخدم إطار عمل أنماط Qiskit:
-الخطوة 1: تحويل المسألة إلى دوائر كمية ومؤثّرات -الخطوة 2: التحسين لعتاد الهدف -الخطوة 3: التنفيذ على عتاد الهدف -الخطوة 4: المعالجة اللاحقة للنتائج
3.1 الخطوة 1: تحويل المسألة إلى دوائر كمية ومؤثّرات
سنستخدم الهاميلتوني الذي عرّفناه أعلاه من السياق الكيميائي. نبدأ ببعض الاستيرادات العامة.
# General imports
import numpy as np
# SciPy minimizer routine
from scipy.optimize import minimize
# Plotting functions
import matplotlib.pyplot as plt
مجدّدًا، نفترض أن الهاميلتوني المراد معروف. سنستخدم هنا هاميلتونيًا صغيرًا للغاية، لأن الأساليب الأخرى التي ستُناقش في هذه الدورة ستكون أكثر كفاءةً في حلّ المسائل الأكبر.
from qiskit.quantum_info import SparsePauliOp
import numpy as np
hamiltonian = SparsePauliOp.from_list(
[("YZ", 0.3980), ("ZI", -0.3980), ("ZZ", -0.0113), ("XX", 0.1810)]
)
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues))
The ground state energy is -0.702930394459531
توجد خيارات كثيرة جاهزة للنموذج الأوّلي في Qiskit. سنستخدم efficient_su2.
# Pre-defined ansatz circuit and operator class for Hamiltonian
from qiskit.circuit.library import efficient_su2
# Note that it is more common to place initial 'h' gates outside the ansatz.
# Here we specifically wanted this layer structure.
ansatz = efficient_su2(
hamiltonian.num_qubits, su2_gates=["h", "rz", "y"], entanglement="circular", reps=1
)
num_params = ansatz.num_parameters
print("This circuit has ", num_params, "parameters")
ansatz.decompose().draw("mpl", style="iqp")
This circuit has 4 parameters
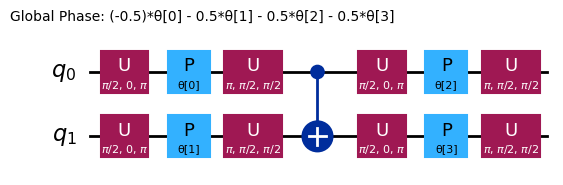
ستمتلك النماذج الأوّلية المختلفة بنى تشابك مختلفة وبوّابات دوران مختلفة. النموذج المعروض هنا يستخدم بوّابات CNOT للتشابك، وكلًّا من بوّابات Y وبوّابات RZ ذات المعاملات للدورانات. لاحظ حجم فضاء المعاملات هذا؛ فهذا يعني أنه يجب علينا تصغير دالة التكلفة على 4 متغيّرات (معاملات بوّابات RZ). يمكن تكبير هذا، لكن ليس إلى ما لا نهاية. تشغيل مسألة مماثلة على 4 كيوبتات، باستخدام 3 تكرارات افتراضية لـefficient_su2، يُنتج 16 معاملًا تباينيًا.
3.2 الخطوة 2: التحسين لعتاد الهدف
كُتب النموذج الأوّلي باستخدام بوّابات مألوفة، لكن دائرتنا يجب أن تُحوَّل (transpile) لاستخدام البوّابات الأساسية التي يمكن تنفيذها على كلّ حاسوب كمي. نختار الواجهة الخلفية الأقلّ انشغالًا.
# runtime imports
from qiskit_ibm_runtime import QiskitRuntimeService, Session
from qiskit_ibm_runtime import EstimatorV2 as Estimator
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend)
<IBMBackend('ibm_torino')>
يمكننا الآن تحويل دائرتنا لهذا العتاد ورؤية النموذج الأوّلي المحوَّل.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
ansatz_isa = pm.run(ansatz)
ansatz_isa.draw(output="mpl", idle_wires=False, style="iqp")

لاحظ أن البوّابات المستخدمة قد تغيّرت، وأن الكيوبتات في دائرتنا المجرّدة أصبحت مُعيَّنة إلى كيوبتات مرقَّمة بشكل مختلف على الحاسوب الكمي. يجب أن نُحوِّل الهاميلتوني بالطريقة ذاتها حتى تكون نتائجنا ذات معنى.
hamiltonian_isa = hamiltonian.apply_layout(layout=ansatz_isa.layout)
3.3 الخطوة 3: التنفيذ على عتاد الهدف
3.3.1 الإبلاغ عن القيم
نُعرِّف هنا دالة تكلفة تأخذ كوسائط البنى التي أعددناها في الخطوات السابقة: المعاملات، والنموذج الأوّلي، والهاميلتوني. وتستخدم أيضًا Estimator الذي لم نُعرِّفه بعد. نُضمِّن كودًا لتتبّع سجلّ دالة التكلفة حتى نتمكّن من فحص سلوك التقارب.
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from Estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (EstimatorV2): Estimator primitive instance
cost_history_dict: Dictionary for storing intermediate results
Returns:
float: Energy estimate
"""
pub = (ansatz, [hamiltonian], [params])
result = estimator.run(pubs=[pub]).result()
energy = result[0].data.evs[0]
cost_history_dict["iters"] += 1
cost_history_dict["prev_vector"] = params
cost_history_dict["cost_history"].append(energy)
print(f"Iters. done: {cost_history_dict['iters']} [Current cost: {energy}]")
return energy
cost_history_dict = {
"prev_vector": None,
"iters": 0,
"cost_history": [],
}
من المفيد جدًا اختيار قيم ابتدائية للمعاملات بناءً على معرفتك بالمسألة وخصائص الحالة المستهدفة. لن نفترض هنا أيّ معرفة مسبقة وسنستخدم قيمًا ابتدائية عشوائية.
x0 = 2 * np.pi * np.random.random(num_params)
# This required 13 min, 20 s QPU time on an Eagle processor, 28 min total time.
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
estimator.options.default_shots = 10000
res = minimize(
cost_func,
x0,
args=(ansatz_isa, hamiltonian_isa, estimator),
method="cobyla",
options={"maxiter": 50},
)
Iters. done: 1 [Current cost: 0.010575798722044727]
Iters. done: 2 [Current cost: 0.004040015974440895]
Iters. done: 3 [Current cost: 0.0020213258785942503]
Iters. done: 4 [Current cost: 0.18723082446726014]
Iters. done: 5 [Current cost: -0.2746792152068885]
Iters. done: 6 [Current cost: -0.3094547651648519]
Iters. done: 7 [Current cost: -0.05281985428356641]
Iters. done: 8 [Current cost: 0.00808560303514377]
Iters. done: 9 [Current cost: -0.0014821685303514388]
Iters. done: 10 [Current cost: -0.004759824281150161]
Iters. done: 11 [Current cost: 0.09942328705995292]
Iters. done: 12 [Current cost: 0.01092366214057508]
Iters. done: 13 [Current cost: 0.05017497496069776]
Iters. done: 14 [Current cost: 0.13028868414310696]
Iters. done: 15 [Current cost: 0.013747803514376994]
Iters. done: 16 [Current cost: 0.2583072432944498]
Iters. done: 17 [Current cost: -0.14422125655131562]
Iters. done: 18 [Current cost: -0.0004950150347678081]
Iters. done: 19 [Current cost: 0.00681082268370607]
Iters. done: 20 [Current cost: -0.0023377795527156544]
Iters. done: 21 [Current cost: 0.6027665591169237]
Iters. done: 22 [Current cost: 0.00596641373801917]
Iters. done: 23 [Current cost: -0.008318769968051117]
Iters. done: 24 [Current cost: -0.00026683306709265246]
Iters. done: 25 [Current cost: -0.007648222843450479]
Iters. done: 26 [Current cost: 0.004121086261980831]
Iters. done: 27 [Current cost: -0.004075019968051117]
Iters. done: 28 [Current cost: -0.004419369009584665]
Iters. done: 29 [Current cost: 0.213185460054037]
Iters. done: 30 [Current cost: -0.06505919572162797]
Iters. done: 31 [Current cost: -0.5334241316590271]
Iters. done: 32 [Current cost: 0.00218370607028754]
Iters. done: 33 [Current cost: 0.09579352143666908]
Iters. done: 34 [Current cost: -0.009274800319488819]
Iters. done: 35 [Current cost: -0.44395141360688106]
Iters. done: 36 [Current cost: 0.011747104632587858]
Iters. done: 37 [Current cost: -0.003344149361022364]
Iters. done: 38 [Current cost: 0.19138183916486304]
Iters. done: 39 [Current cost: 0.013513931813145209]
يمكننا الاطّلاع على المخرجات الخام.
res
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.5334241316590271
x: [ 1.024e+00 6.459e+00 3.625e+00 4.007e+00]
nfev: 39
maxcv: 0.0
3.4 الخطوة 4: المعالجة اللاحقة للنتائج
إذا انتهى الإجراء بشكل صحيح، فإن القيم في قاموسنا يجب أن تساوي متّجه الحلّ وعدد تقييمات الدالة الإجمالي على التوالي. يسهل التحقّق من ذلك:
cost_history_dict
{'prev_vector': array([1.02397956, 6.45886604, 3.62479262, 4.00744128]),
'iters': 39,
'cost_history': [np.float64(0.010575798722044727),
np.float64(0.004040015974440895),
np.float64(0.0020213258785942503),
np.float64(0.18723082446726014),
np.float64(-0.2746792152068885),
np.float64(-0.3094547651648519),
np.float64(-0.05281985428356641),
np.float64(0.00808560303514377),
np.float64(-0.0014821685303514388),
np.float64(-0.004759824281150161),
np.float64(0.09942328705995292),
np.float64(0.01092366214057508),
np.float64(0.05017497496069776),
np.float64(0.13028868414310696),
np.float64(0.013747803514376994),
np.float64(0.2583072432944498),
np.float64(-0.14422125655131562),
np.float64(-0.0004950150347678081),
np.float64(0.00681082268370607),
np.float64(-0.0023377795527156544),
np.float64(0.6027665591169237),
np.float64(0.00596641373801917),
np.float64(-0.008318769968051117),
np.float64(-0.00026683306709265246),
np.float64(-0.007648222843450479),
np.float64(0.004121086261980831),
np.float64(-0.004075019968051117),
np.float64(-0.004419369009584665),
np.float64(0.213185460054037),
np.float64(-0.06505919572162797),
np.float64(-0.5334241316590271),
np.float64(0.00218370607028754),
np.float64(0.09579352143666908),
np.float64(-0.009274800319488819),
np.float64(-0.44395141360688106),
np.float64(0.011747104632587858),
np.float64(-0.003344149361022364),
np.float64(0.19138183916486304),
np.float64(0.013513931813145209)]}
fig, ax = plt.subplots()
x = np.linspace(0, 10, 50)
# Define the constant function
constant = -0.7029
y_constant = np.full_like(x, constant)
ax.plot(
range(cost_history_dict["iters"]), cost_history_dict["cost_history"], label="VQE"
)
ax.set_xlabel("Iterations")
ax.set_ylabel("Cost")
ax.plot(y_constant, label="Target")
plt.legend()
plt.draw()

تقدّم IBM Quantum عروضًا أخرى لتطوير المهارات المتعلّقة بـVQE. إذا كنت مستعدًا لتطبيق VQE عمليًا، راجع برنامجنا التعليمي: تقدير طاقة الحالة الأساسية لسلسلة هايزنبرغ باستخدام VQE. إذا أردت مزيدًا من المعلومات حول إنشاء هاميلتونيات جزيئية، راجع هذا الدرس في دورتنا عن الكيمياء الكمية مع VQE. إذا كنت مهتمًا بفهم أعمق لكيفية عمل الخوارزميات التباينية مثل VQE، نوصي بدورة تصميم الخوارزميات التباينية.
اختبر فهمك
في هذا القسم، حسبنا طاقة الحالة الأساسية من هاميلتوني. إذا أردنا تطبيق ذلك على تحديد الشكل الهندسي لجزيء مثلًا، كيف سنوسّع هذا؟
Answer
سنحتاج إلى إدخال متغيّرات للمسافات بين الذرّات والزوايا بين الروابط. سيتعيّن علينا تنويع هذه المتغيّرات. ولكلّ تنويع منها، سنُنتج هاميلتونيًا جديدًا (لأن المؤثّرات التي تصف الطاقة تعتمد بالتأكيد على الشكل الهندسي). ولكلّ هاميلتوني يُنتَج ويُحوَّل إلى كيوبتات، سنحتاج إلى إجراء تحسين كالذي أُجري أعلاه. ومن بين كلّ تلك المسائل المحسَّنة المتقاربة، سيكون الشكل الهندسي الذي أنتج أدنى طاقة هو ما تتبنّاه الطبيعة. هذا أكثر تعقيدًا بكثير مما عُرض أعلاه. يُجرى مثل هذا الحساب لأبسط جزيء، ، هنا.
4. علاقة VQE بالأساليب الأخرى
سنستعرض في هذا القسم مزايا وعيوب نهج VQE الأصلي ونشير إلى علاقته بالخوارزميات الأخرى الأحدث.
4.1 نقاط القوة والضعف في VQE
سبق أن أشرنا إلى بعض نقاط القوة، وتشمل:
- الملاءمة للعتاد الحالي: بعض الخوارزميات الكمية تتطلّب معدّلات خطأ أدنى بكثير تقترب من التسامح الخطأي واسع النطاق. أما VQE فلا تتطلّب ذلك؛ إذ يمكن تنفيذها على الحواسيب الكمية الحالية.
- الدوائر الضحلة: كثيرًا ما تستخدم VQE دوائر كمية ضحلة نسبيًا. مما يجعلها أقلّ عرضةً لأخطاء البوّابات المتراكمة وملائمةً لكثير من تقنيات تخفيف الأخطاء. بالطبع، الدوائر ليست دائمًا ضحلة؛ فهذا يعتمد على النموذج الأوّلي المُستخدم.
- التنوّع: يمكن (من حيث المبدأ) تطبيق VQE على أيّ مسألة يمكن صياغتها كمسألة قيمة ذاتية/متّجه ذاتي. هناك تحفّظات كثيرة تجعل VQE غير عملية أو غير مُجدية لبعض المسائل. يُلخَّص بعضها أدناه.
كما وُصفت أعلاه بعض نقاط ضعف VQE والمسائل التي تكون فيها غير عملية، وتشمل:
- الطبيعة الاستدلالية: لا تضمن VQE التقارب إلى طاقة الحالة الأساسية الصحيحة، إذ يعتمد أداؤها على اختيار النموذج الأوّلي وأساليب التحسين[1-2]. إذا اختير نموذج أوّلي ضعيف يفتقر إلى التشابك اللازم للحالة الأساسية المطلوبة، فلن يستطيع أيّ مُحسِّن كلاسيكي الوصول إلى تلك الحالة.
- كثرة المعاملات المحتملة: قد يحتوي نموذج أوّلي شديد التعبيرية على معاملات كثيرة جدًا تجعل تكرارات التصغير مُكلفة زمنيًا.
- العبء القياسي الكبير: في VQE، يُستخدم Estimator لتقدير قيمة التوقّع لكلّ حدٍّ في الهاميلتوني. معظم الهاميلتونيات المهمّة تحتوي على حدود لا يمكن تقديرها في آنٍ واحد. مما قد يجعل VQE مُكلفة المَوارد للأنظمة الكبيرة ذات الهاميلتونيات المعقّدة[1].
- تأثيرات الضوضاء: حين يبحث المُحسِّن الكلاسيكي عن نقطة صغرى، قد تُربكه الحسابات الضوضائية وتحرفه عن النقطة الصغرى الحقيقية أو تؤخّر تقاربه. أحد الحلول الممكنة هو الاستفادة من أحدث تقنيات تخفيف الأخطاء وكبتها[2-3] من IBM.
- الهضاب القاحلة: هذه المناطق ذات التدرّجات المتلاشية[2-3] موجودة حتى في غياب الضوضاء، لكن الضوضاء تجعلها أكثر إشكالية لأن تغيّر قيم التوقّع الناتج عن الضوضاء قد يكون أكبر من التغيّر الناتج عن تحديث المعاملات في هذه المناطق.
4.2 العلاقة بالأساليب الأخرى
Adapt-VQE
خوارزمية ADAPT-VQE (خوارزمية التباين الكمي لإيجاد القيمة الذاتية بتجميع مشتقّ تكيّفي شبه تروتري) هي تحسين لخوارزمية VQE الأصلية، مُصمَّمة لتعزيز الكفاءة والدقّة وقابلية التوسّع في المحاكاة الكمية، لا سيّما في الكيمياء الكمية.
خوارزمية VQE الأصلية الموصوفة في هذا الدرس تستخدم نموذجًا أوّليًا ثابتًا مُحدَّدًا مسبقًا لتقريب الحالة الأساسية للنظام. في حالتنا، استخدمنا efficient_su2 بتكرار واحد وبوّابات دوران Y و RZ. ورغم أن المعاملات في بوّابات RZ تغيّرت، إلا أن بنية هذا النموذج الأوّلي والبوّابات المستخدمة لم تتغيّر.
تُعالج ADAPT-VQE قيود VQE عبر بناء نموذج أوّلي تكيّفي. بدلًا من البدء بنموذج أوّلي ثابت، تبني ADAPT-VQE النموذج الأوّلي ديناميكيًا بشكل تكراري. في كلّ خطوة، تختار المؤثّر من مجموعة مُعرَّفة مسبقًا (كمؤثّرات الإثارة الفرميونية) الذي يمتلك أكبر تدرّج بالنسبة للطاقة. مما يضمن إضافة المؤثّرات الأكثر تأثيرًا فحسب، ويُنتج نموذجًا أوّليًا مضغوطًا وفعّالًا[4-6]. يمكن أن يكون لهذا النهج عدّة تأثيرات إيجابية:
- تقليل عمق الدائرة: ببناء النموذج الأوّلي تدريجيًا والتركيز فقط على المؤثّرات الضرورية، تُقلّل ADAPT-VQE عمليات البوّابات مقارنةً بنُهج VQE التقليدية[5,7].
- تحسين الدقّة: تتيح الطبيعة التكيّفية لـADAPT-VQE استرداد مزيد من طاقة الارتباط في كلّ خطوة، مما يجعلها فعّالة بشكل خاص للأنظمة ذات الارتباط القوي حيث تواجه VQE التقليدية صعوبات[8,9].
- قابلية التوسّع ومتانة أمام الضوضاء: يُقلّل النموذج الأوّلي المضغوط من تراكم أخطاء البوّابات، ويخفض العبء الحسابي، ويحدّ من عدد المعاملات التباينية التي يجب تصغيرها.
ADAPT-VQE ليست مثالية بدورها. في بعض الحالات قد تعلق أو تتباطأ بسبب الحدود الصغرى المحلية، وقد تعاني من فرط المعاملات. كما يمكن أن تكون مُكلفة المَوارد إلى حدٍّ ما، إذ تتطلّب حساب التدرّجات وتحسين المعاملات مع بنى بوّابات كثيرة.
تقدير الطور الكمي (QPE)
QPE مشابه في الغرض لـVQE لكنّه مختلف جدًا في التنفيذ. يتطلّب QPE حواسيب كمية متسامحة مع الأخطاء بسبب دوائره الكمية العميقة عمومًا والمستوى العالي من التماسك الذي يحتاجه. بمجرّد أن يصبح تنفيذ QPE ممكنًا، سيكون أدقّ من VQE. إحدى طرق وصف الفرق هي عبر الدقّة كدالة لعمق الدائرة. يحقّق QPE دقّة بعمق دائرة يتوسّع كـ [10]. أما VQE فتتطلّب عيّنة لتحقيق الدقّة ذاتها[10,11].
كريلوف، SQD، QSCI، وخوارزميات أخرى في هذه الدورة
ساعدت VQE في ترسيخ الخوارزميات الكمية التي لا تزال تعتمد على الحواسيب الكلاسيكية، ليس فقط لتشغيل الحاسوب الكمي بل لأجزاء جوهرية من الخوارزمية. عدّة خوارزميات من هذا النوع هي محور ما تبقّى من هذه الدورة. نقدّم هنا شرحًا موجزًا لبعضها، فقط للمقارنة والمقابلة مع VQE. سيُشرح كلٌّ منها بتفصيل أكبر بكثير في الدروس اللاحقة.
قطرنة كريلوف الكمومية (KQD)
أساليب فضاء كريلوف الجزئي هي طرق لإسقاط مصفوفة على فضاء جزئي لتقليل بُعدها وجعلها أسهل في التعامل، مع الحفاظ على أهمّ السمات. إحدى الحيل في هذا الأسلوب هي توليد فضاء جزئي يحتفظ بهذه السمات؛ واتّضح أن توليد هذا الفضاء الجزئي مرتبط ارتباطًا وثيقًا بأسلوب راسخ على الحواسيب الكمية يُسمّى تروتيريزيشن.
توجد عدّة متغيّرات من أساليب كريلوف الكمية، لكن النهج العام هو:
- استخدام الحاسوب الكمي لتوليد فضاء جزئي (فضاء كريلوف الجزئي) عبر تروتيريزيشن
- إسقاط المصفوفة المراد دراستها على ذلك الفضاء الجزئي
- قطرنة الهاميلتوني المُسقَط الجديد باستخدام حاسوب كلاسيكي
القطرنة الكمومية القائمة على أخذ العيّنات (SQD)
القطرنة الكمومية القائمة على أخذ العيّنات (SQD) مرتبط بأسلوب كريلوف في أنه يحاول أيضًا تقليل بُعد المصفوفة المراد قطرنةها مع الحفاظ على السمات الأساسية. يفعل SQD ذلك بالطريقة التالية:
- ابدأ بتخمين أوّلي لحالتك الأساسية وأعدّ النظام في تلك الحالة.
- استخدم Sampler لأخذ عيّنات من سلاسل البتات المكوِّنة لهذه الحالة.
- استخدم مجموعة حالات الأساس الحسابية من Sampler كفضاء جزئي تُسقط عليه مصفوفتك المراد دراستها.
- قطّر المصفوفة الأصغر المُسقطة باستخدام حاسوب كلاسيكي.
هذا مرتبط بـVQE في أنه يستفيد من الحوسبة الكلاسيكية والكمية لمكوّنات جوهرية في الخوارزمية. كلاهما يشترك أيضًا في متطلّب إعداد تخمين أوّلي أو نموذج أوّلي جيّد. لكن توزيع العمل بين الحاسوبَين الكلاسيكي والكمي في SQD يشبه أكثر توزيعه في أسلوب كريلوف.
في الواقع، دُمج أسلوبا كريلوف وSQD مؤخّرًا في أسلوب قطرنة كريلوف الكمومية القائم على أخذ العيّنات (SKQD) [12].
تفاعل التكوينات الكمي المُنتقى
تفاعل التكوينات الكمي المُنتقى (QSCI)[13] هو خوارزمية تُنتج حالة أساسية مُقرّبة لهاميلتوني عن طريق أخذ عيّنات من دالة موجية تجريبية لتحديد حالات الأساس الحسابية المهمّة وتوليد فضاء جزئي للقطرنة الكلاسيكي. يستخدم كلٌّ من SQD وQSCI الحاسوب الكمي لبناء فضاء جزئي مُختزَل. القوة الإضافية لـQSCI تكمن في إعداد الحالة، خصوصًا في سياق مسائل الكيمياء. فهي تستفيد من استراتيجيات متنوّعة مثل استخدام حالات متطوّرة زمنيًا[14] ومجموعة من النماذج الأوّلية المُلهَمة من الكيمياء. ومن خلال التركيز على إعداد الحالة بكفاءة، يُخفّض QSCI التكاليف الحسابية الكمية للهاميلتونيات الكيميائية مع الحفاظ على دقّة عالية والاستفادة من المتانة أمام الضوضاء الناتجة عن تقنيات أخذ العيّنات الكمية[15]. كما يوفّر QSCI تقنية بناء تكيّفية تُقدّم مزيدًا من النماذج الأوّلية لنتائج أفضل.
سير العمل الافتراضي لـQSCI لمسائل الكيمياء هو كالتالي:
- بناء الهاميلتوني الجزيئي باستخدام البرنامج الذي تختاره (مثل SciPy).
- إعداد خوارزمية QSCI باختيار حالة ابتدائية مناسبة ونموذج أوّلي مُلهَم من الكيمياء مع مجموعة مُنتقاة مسبقًا من المعاملات.
- أخذ عيّنات من حالات الأساس المهمّة وقطرنة الهاميلتوني باستخدام حاسوب كلاسيكي للحصول على طاقة الحالة الأساسية.
- غالبًا ما تُستخدم تقنيات استرداد التكوينات[16] والانتقاء اللاحق للتناظر[15] كمعالجة لاحقة.
- اختياريًا، يتضمّن سير عمل QSCI التكيّفي حلقة تحسين إضافية من الخطوة 2 إلى الخطوة 3، باستخدام مزيد من النماذج الأوّلية مع حالات ابتدائية عشوائية.
اختبر فهمك
ما المشترك بين VQE وجميع الأساليب الأخرى المذكورة أعلاه (باستثناء QPE الذي لم يُوصف بالتفصيل)
Answer
جميعها تتضمّن حالة أو دالة موجية تجريبية من نوع ما. وجميعها تعمل بشكل أفضل حين يكون التخمين الأوّلي لهذه الحالة التجريبية ممتازًا.
إجابة صحيحة أخرى هي أنها جميعًا أسهل في التنفيذ حين يكون الهاميلتوني سهل القياس (يمكن تصنيفه في عدد قليل نسبيًا من مجموعات عوامل باولي المتبادلة).
ما الذي تشترك فيه VQE ولا تشترك فيه أيٌّ من الأساليب الأخرى المذكورة أعلاه؟
Answer
المُحسِّنات الكلاسيكية. لا يستخدم أيٌّ من الأساليب الأخرى خوارزميات تحسين كلاسيكية لاختيار المعاملات التباينية.
المراجع
[2] https://en.wikipedia.org/wiki/Variational_quantum_eigensolver
[3] https://journals.aps.org/prapplied/abstract/10.1103/PhysRevApplied.19.024047
[4] https://arxiv.org/abs/2111.05176
[6] https://inquanto.quantinuum.com/tutorials/InQ_tut_fe4n2_2.html
[7] https://www.nature.com/articles/s41467-019-10988-2
[8] https://arxiv.org/abs/2210.15438
[9] https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.6.013254
[10] https://arxiv.org/html/2403.09624v1
[11] https://www.nature.com/articles/s42005-023-01312-y
[13] https://arxiv.org/abs/1802.00171
[14] https://arxiv.org/abs/2103.08505
[15] https://arxiv.org/html/2501.09702v1
[16] https://quri-sdk.qunasys.com/docs/examples/quri-algo-vm/qsci/