ترميز البيانات
المقدمة والترميز الرياضي
لاستخدام خوارزمية كمومية، يجب إدخال البيانات الكلاسيكية بطريقة ما إلى دائرة كمومية. يُشار إلى هذا عادةً بـترميز البيانات، وقد يُسمى أيضاً تحميل البيانات. تذكّر من الدروس السابقة مفهوم تعيين الميزات (feature mapping)، وهو تعيين ميزات البيانات من فضاء إلى آخر. مجرد نقل البيانات الكلاسيكية إلى حاسوب كمومي هو نوع من التعيين، ويمكن تسميته تعيين ميزات. من الناحية العملية، تتضمن تعيينات الميزات المدمجة في Qiskit (مثل z_feature_map وzz_feature_map) عادةً طبقات دوران وطبقات تشابك تمتد بالحالة إلى أبعاد عديدة في فضاء هيلبرت. تُعدّ عملية الترميز هذه جزءاً محورياً من خوارزميات تعلّم الآلة الكمومي وتؤثر مباشرةً في قدراتها الحسابية.
بعض أساليب الترميز التالية يمكن محاكاتها كلاسيكياً بكفاءة؛ ويتضح ذلك جلياً في أساليب الترميز التي تُنتج حالات جداء (أي أنها لا تُشابك الكيوبتات). وتذكّر أن الفائدة الكمومية تكمن على الأرجح في المواضع التي يتطابق فيها التعقيد الكمومي للبيانات مع أسلوب الترميز. لذا من المرجح جداً أن تنتهي إلى كتابة دوائر ترميز خاصة بك. نعرض هنا مجموعة واسعة من استراتيجيات الترميز الممكنة لمقارنتها وفهم الفوارق بينها، والاطلاع على ما هو متاح. ثمة تصريحات عامة يمكن إطلاقها حول مدى فائدة أساليب الترميز. مثلاً، efficient_su2 (انظر أدناه) مع مخطط تشابك كامل أكثر احتمالاً لالتقاط الميزات الكمومية للبيانات مقارنةً بالأساليب التي تُنتج حالات جداء (مثل z_feature_map). لكن هذا لا يعني أن efficient_su2 كافٍ أو متلاءم بما يكفي مع بياناتك لتحقيق تسريع كمومي، إذ يستلزم ذلك دراسة متأنية لبنية البيانات المُنمذَجة أو المُصنَّفة. كما أن ثمة موازنة مع عمق الدائرة، فكثير من تعيينات الميزات التي تُشابك الكيوبتات بالكامل تُنتج دوائر عميقة جداً يتعذّر الحصول منها على نتائج قابلة للاستخدام على أجهزة الكمبيوتر الكمومية الحالية.
الترميز الرياضي
مجموعة البيانات هي مجموعة من متجهات بيانات: ، حيث كل متجه ذو بُعداً، أي . يمكن تعميم هذا ليشمل ميزات البيانات المركّبة. في هذا الدرس، قد نستخدم أحياناً هذه الرموز للمجموعة الكاملة وعناصرها المحددة مثل . لكننا سنتحدث في معظم الأحيان عن تحميل متجه واحد من مجموعة البيانات في كل مرة، وكثيراً ما سنشير فقط إلى متجه واحد مؤلف من ميزة على شكل .
علاوةً على ذلك، يشيع استخدام الرمز للإشارة إلى تعيين الميزات للمتجه . وفي الحوسبة الكمومية تحديداً، يشيع الإشارة إلى التعيينات باستخدام ، وهو ترميز يُبرز الطابع الأحادي لهذه العمليات. يمكن استخدام الرمز نفسه لكليهما بصورة صحيحة؛ فكلاهما تعيين ميزات. في هذه الدورة، نميل إلى استخدام:
- عند الحديث عن تعيينات الميزات في تعلّم الآلة بشكل عام، و
- عند الحديث عن التطبيقات الدائرية لتعيينات الميزات.
التوحيد القياسي وفقدان المعلومات
في تعلّم الآلة الكلاسيكي، كثيراً ما تُوحَّد قياسياً ميزات بيانات التدريب أو تُعاد ضبطها، مما يُحسّن أداء النموذج في الغالب. من أشيع طرق ذلك التوحيد القياسي بالحد الأدنى والأقصى (min-max normalization) أو التوحيد القياسي الإحصائي (standardization). في التوحيد بالحد الأدنى والأقصى، تُوحَّد أعمدة الميزات في مصفوفة البيانات (مثلاً الميزة ) على النحو التالي:
حيث تشير min وmax إلى الحد الأدنى والأقصى للميزة عبر متجهات البيانات في مجموعة البيانات . تقع جميع قيم الميزات بعدها في الفترة الوحدوية: لكل , .
التوحيد القياسي مفهوم أساسي أيضاً في ميكانيكا الكم والحوسبة الكمومية، لكنه يختلف قليلاً عن التوحيد بالحد الأدنى والأقصى. يشترط التوحيد في ميكانيكا الكم أن يكون طول (في سياق الحوسبة الكمومية، المعيار-2) متجه الحالة مساوياً للوحدة: ، مما يضمن أن مجموع احتمالات القياس يساوي 1. تُوحَّد الحالة بالقسمة على المعيار-2، أي بإعادة الضبط:
في الحوسبة الكمومية وميكانيكا الكم، هذا ليس توحيداً يفرضه الناس على البيانات، بل خاصية أساسية لحالات الكم. اعتماداً على مخطط الترميز لديك، قد يؤثر هذا القيد على طريقة إعادة ضبط بياناتك. مثلاً، في الترميز بالسعة (انظر أدناه)، يُوحَّد متجه البيانات كما تقتضي ميكانيكا الكم، وهذا يؤثر في ضبط البيانات المُرمَّزة. أما في الترميز بالطور، فيُوصى بإعادة ضبط قيم الميزات بحيث لتجنب فقدان المعلومات الناجم عن تأثير modulo- عند الترميز على زاوية طور الكيوبت[1,2].
أساليب الترميز
في الأقسام القليلة التالية، سنشير إلى مجموعة بيانات كلاسيكية مثالية صغيرة تتألف من متجهات بيانات، لكل منها ميزات:
بالترميز المقدَّم أعلاه، نقول مثلاً إن الميزة للمتجه الرابع في مجموعتنا هي .
الترميز بالأساس
يُرمَّز في الترميز بالأساس سلسلة بتات كلاسيكية مؤلفة من بت في حالة أساس حسابية لنظام مؤلف من كيوبت. خذ مثلاً . يمكن تمثيل هذا كسلسلة مؤلفة من بتات على النحو ، وبنظام مؤلف من كيوبتات كحالة كمومية . بشكل عام، لسلسلة بتات مؤلفة من بت: ، تكون الحالة المقابلة لـ كيوبت هي مع لـ. لاحظ أن هذا لميزة واحدة فقط.
في الترميز بالأساس الكمومي، يُمثَّل كل بت كلاسيكي بكيوبت منفصل، إذ تُعيَّن التمثيلات الثنائية للبيانات مباشرةً على الحالات الكمومية في الأساس الحسابي. عند الحاجة إلى ترميز ميزات متعددة، تُحوَّل كل ميزة أولاً إلى شكلها الثنائي ثم تُعيَّن إلى مجموعة مستقلة من الكيوبتات — مجموعة لكل ميزة — حيث يعكس كل كيوبت بتاً في التمثيل الثنائي لتلك الميزة.
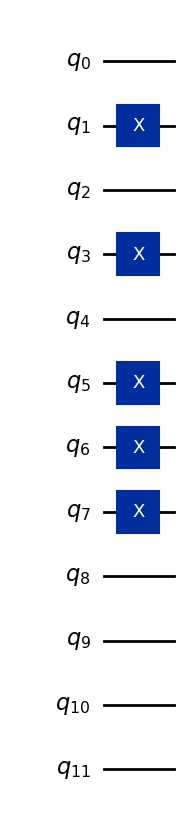
كمثال، لنرمّز المتجه (5, 7, 0).
لنفترض أن جميع الميزات مخزَّنة في أربعة بتات (أكثر مما نحتاج، لكن كافٍ لتمثيل أي عدد صحيح أحادي الرقم بالأساس 10):
5 → binary 0101
7 → binary 0111
0 → binary 0000
تُعيَّن سلاسل البتات هذه إلى ثلاث مجموعات من أربعة كيوبتات، فتكون حالة الأساس الكلية لـ12 كيوبتاً:
هنا، تمثّل الكيوبتات الأربع الأولى الميزة الأولى، والأربع التالية الميزة الثانية، والأربع الأخيرة الميزة الثالثة. يُحوِّل الكود التالي متجه البيانات (5,7,0) إلى حالة كمومية، وهو مُعمَّم للقيام بذلك مع ميزات أحادية الرقم أخرى.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
تحقق من فهمك
اقرأ السؤال أدناه، فكّر في إجابتك، ثم انقر على المثلث للكشف عن الحل.
اكتب كوداً لترميز المتجه الأول في مجموعة البيانات المثالية :
باستخدام الترميز بالأساس.
الإجابة:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
الترميز بالسعة
الترميز بالسعة يُشفِّر البيانات في سعات (amplitudes) الحالة الكمومية. فهو يُمثِّل متجهَ بيانات كلاسيكيًا مُعيَّنًا بُعده ، وهو ، على شكل سعات لحالة كمومية مكوَّنة من كيوبت، :
حيث هو نفس بُعد متجهات البيانات المذكورة سابقًا، و هو العنصر في ، و هو حالة الأساس الحسابية . أما فهو ثابت التسوية (normalization constant) الذي يُحدَّد من البيانات المُشفَّرة. وهذا هو شرط التسوية الذي تفرضه ميكانيكا الكم:
بشكل عام، هذا الشرط يختلف عن تسوية min/max المُستخدمة لكل ميزة عبر جميع متجهات البيانات. وكيفية التعامل مع هذا الاختلاف تعتمد على المسألة التي تعمل عليها، لكن لا مفر من شرط التسوية الكمومية أعلاه.
في الترميز بالسعة، كل ميزة في متجه البيانات تُخزَّن كسعة لحالة كمومية مختلفة. وبما أن نظامًا من كيوبت يوفر سعة، فإن ترميز ميزة بالسعة يتطلب كيوبت.
كمثال، لنُشفِّر المتجه الأول في مجموعة بياناتنا ، وهو ، باستخدام الترميز بالسعة. بعد تسوية المتجه الناتج، نحصل على:
والحالة الكمومية المكوَّنة من كيوبتين الناتجة ستكون:
في المثال أعلاه، عدد الميزات في المتجه ليس قوة للعدد 2. حين لا يكون قوة للعدد 2، نختار ببساطة قيمة لعدد الكيوبتات بحيث ، ونملأ متجه السعة بثوابت غير معلوماتية (هنا، صفر).
كما في الترميز الأساسي، بمجرد حساب الحالة التي ستُشفِّر مجموعة بياناتنا، يمكننا في Qiskit استخدام دالة initialize لتهيئتها:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

ميزة الترميز بالسعة هي الاكتفاء بـ كيوبت فقط كما ذُكر سابقًا. غير أن الخوارزميات اللاحقة يجب أن تعمل على سعات الحالة الكمومية، وطرق تهيئة الحالات الكمومية وقياسها لا تكون عادةً ذات كفاءة عالية.
اختبر فهمك
اقرأ الأسئلة أدناه، فكِّر في إجاباتك، ثم اضغط على المثلثات للكشف عن الحلول.
اكتب الحالة المُسوَّاة لترميز المتجه التالي (المكوَّن من متجهين من مجموعة بياناتنا):
باستخدام الترميز بالسعة.
الإجابة:
لترميز 6 أعداد، نحتاج إلى امتلاك 6 حالات على الأقل يمكننا ترميز السعات عليها. وهذا يتطلب 3 كيوبتات. باستخدام عامل تسوية غير معروف ، يمكننا كتابة ذلك على النحو التالي:
لاحظ أن
وأخيرًا،
لنفس متجه البيانات اكتب كودًا لإنشاء دائرة تُحمِّل هذه الميزات باستخدام الترميز بالسعة.
الإجابة:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

قد تحتاج إلى التعامل مع متّجهات بيانات كبيرة جدًا. تأمّل المتّجه التالي:
اكتب كودًا لأتمتة عملية التطبيع، وأنشئ دائرة كمومية لترميز السّعة.
الجواب:
هناك إجابات عديدة محتملة. إليك كودًا يطبع بعض الخطوات الوسيطة:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
المصفوفة بعد التطبيع: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
هل ترى مزايا لترميز السّعة مقارنةً بترميز الأساس؟ إن كان الأمر كذلك، فاشرح.
الجواب:
قد تكون هناك إجابات عدة. إحدى الإجابات هي أنّه بالنظر إلى الترتيب الثابت لحالات الأساس، فإنّ ترميز السّعة هذا يحافظ على ترتيب الأعداد المُرمَّزة. وغالبًا ما يكون الترميز أكثر كثافة أيضًا.
من مزايا ترميز السّعة أنّه لا يتطلّب سوى كيوبت لمتّجه بيانات ذي بُعدًا ( ميزة) . غير أنّ ترميز السّعة هو بشكل عام إجراءٌ غير كفء يستلزم تحضير حالة اعتباطية، وهو ما يكون أسيًّا في عدد بوابات CNOT. بعبارة أخرى، تتمتّع عملية تحضير الحالة بتعقيد زمني متعدّد الحدود يُقدَّر بـ بالنسبة إلى عدد الأبعاد، حيث ، و هو عدد الكيوبتات. يُتيح ترميز السّعة "توفيرًا أسيًّا في الفضاء على حساب زيادة أسيّة في الزمن"[3]؛ بيد أنّ تحقيق تعقيد زمني بمرتبة ممكن في حالات معيّنة[4]. ولتحقيق تسريع كمومي شامل من البداية حتى النهاية، يجب أخذ تعقيد زمن تحميل البيانات بعين الاعتبار.
ترميز الزاوية
يحظى ترميز الزاوية باهتمام واسع في كثير من نماذج QML التي تستخدم خرائط ميزات باولي، كآلات المتّجهات الداعمة الكمومية (QSVMs) والدوائر الكمومية التغايرية (VQCs) وغيرها. ويرتبط ترميز الزاوية ارتباطًا وثيقًا بترميز الطور وترميز الزاوية الكثيف اللذين سنعرضهما لاحقًا. سنستخدم هنا مصطلح "ترميز الزاوية" للإشارة إلى دوران في ، أي دوران بعيدًا عن محور ، يتحقّق مثلًا ببوابة أو بوابة [1,3]. في الواقع، يمكن ترميز البيانات في أيّ دوران أو مزيج من الدورانات، إلّا أنّ هي الأكثر شيوعًا في الأدبيات، لذا سنُركّز عليها هنا.
عند تطبيق ترميز الزاوية على كيوبت واحد، فإنّه يُضفي دورانًا حول محور Y يتناسب مع قيمة البيانات. تأمّل ترميز ميزة واحدة (الميزة رقم ) من متّجه البيانات في مجموعة البيانات، :
بدلًا من ذلك، يمكن إجراء ترميز الزاوية باستخدام بوابات ، وإن كانت الحالة المُرمَّزة ستمتلك عندئذٍ طورًا نسبيًّا مركّبًا مقارنةً بـ .
يختلف ترميز الزاوية عن الطريقتين السابقتين من عدّة نواحٍ. في ترميز الزاوية:
- تُربَط كل قيمة ميزة بكيوبت مقابل لها، ، ممّا يُبقي الكيوبتات في حالة جداء.
- يُرمَّز قيمة عددية واحدة في كل مرة، بدلًا من مجموعة ميزات كاملة من نقطة بيانات.
- يتطلّب ترميز ميزة بيانات كيوبت، حيث . وفي الغالب يتحقّق التساوي هنا. سنرى كيف يمكن أن يكون في الأقسام القليلة التالية.
- الدائرة الكمومية الناتجة تمتلك عمقًا ثابتًا (عادةً يكون العمق 1 قبل عملية التحويل).
تجعل الدائرة الكمومية ذات العمق الثابت ترميزَ الزاوية مناسبًا بشكل خاص للأجهزة الكمومية الحالية. ميزة إضافية أخرى لترميز بياناتنا باستخدام (وتحديدًا، اختيارنا لترميز الزاوية حول محور Y) هي أنّه يُنشئ حالات كمومية ذات قيم حقيقية قد تكون مفيدة في بعض التطبيقات. في دوران محور Y، يُعيَّن ترميز البيانات بوّابة دوران حول محور Y مُعطاة بـ بزاوية حقيقية (Qiskit RYGate). وكما هو الحال مع ترميز الطور (انظر أدناه)، نوصي بإعادة قياس البيانات بحيث ، تفاديًا لفقدان المعلومات وغيره من التأثيرات غير المرغوبة.
يُدوِّر كود Qiskit التالي كيوبتًا واحدًا من حالته الابتدائية لترميز قيمة البيانات .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
سنُعرِّف دالة لتصوير تأثير العملية على متّجه الحالة. تفاصيل تعريف الدالة ليست مهمة، لكنّ القدرة على تصوير متّجهات الحالة وتغيّراتها أمرٌ بالغ الأهمية.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

هذا كان مجرد ميزة واحدة من متجه بيانات واحد. عند ترميز ميزة في زوايا الدوران لـ كيوبت، لنقل للمتجه الـ من البيانات سيبدو حالة الجداء المُرمَّزة هكذا:
نلاحظ أن هذا مكافئ لـ
تحقق من فهمك
اقرأ الأسئلة أدناه، فكّر في إجاباتك، ثم انقر على المثلثات للكشف عن الحلول.
رمّز متجه البيانات باستخدام الترميز الزاوي كما هو موضح أعلاه.
الجواب:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

باستخدام الترميز الزاوي كما هو موضح أعلاه، كم عدد الكيوبتات المطلوبة لترميز 5 ميزات؟
الجواب: 5
الترميز بالطور
الترميز بالطور مشابه جداً للترميز الزاوي الموضح أعلاه. زاوية طور الكيوبت هي زاوية حقيقية القيمة حول المحور من المحور . تُعيَّن البيانات باستخدام دوران الطور، ، حيث (راجع Qiskit PhaseGate لمزيد من المعلومات). يُنصح بإعادة تحجيم البيانات بحيث يكون . هذا يمنع فقدان المعلومات وتأثيرات أخرى غير مرغوب فيها[1,2].
عادةً ما يُهيَّأ الكيوبت في الحالة ، وهي حالة ذاتية لمؤثر دوران الطور، مما يعني أن حالة الكيوبت تحتاج أولاً إلى التدوير حتى يمكن تطبيق الترميز بالطور. لذلك من المنطقي تهيئة الحالة ببوابة هادامار: . الترميز بالطور على كيوبت واحد يعني إضافة طور نسبي يتناسب مع قيمة البيانات:
تعيّن إجراءات الترميز بالطور كل قيمة ميزة إلى طور الكيوبت المقابل، . في المجمل، يمتلك الترميز بالطور عمق دائرة مقداره 2، بما في ذلك طبقة هادامار، مما يجعله مخطط ترميز فعّال. الحالة متعددة الكيوبتات المُرمَّزة بالطور ( كيوبت لـ ميزة) هي حالة جداء:
كود Qiskit التالي يُهيِّئ أولاً الحالة الابتدائية لكيوبت واحد بتدويره ببوابة هادامار، ثم يدوّره مجدداً باستخدام بوابة الطور لترميز ميزة البيانات .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

يمكننا تصور الدوران في باستخدام دالة plot_Nstates التي عرّفناها.
plot_Nstates(states, axis=None, plot_trace_points=True)

مخطط كرة بلوخ يُظهر دوران المحور Z على الشكل حيث . يُشير السهم الأخضر الفاتح إلى الحالة النهائية.
يُستخدم الترميز الطوري في كثير من خرائط الميزات الكمومية، خاصةً خرائط الميزات و، وخرائط ميزات باولي العامة، وغيرها.
تحقق من فهمك
اقرأ الأسئلة أدناه، فكّر في إجاباتك، ثم انقر على المثلثات لعرض الحلول.
كم عدد الكيوبتات المطلوبة لاستخدام الترميز الطوري كما هو موضح أعلاه لتخزين 8 ميزات؟
الجواب: 8
اكتب كوداً لترميز المتجه باستخدام الترميز الطوري.
الجواب:
قد تكون هناك إجابات متعددة. إليك مثال واحد:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

الترميز بالزاوية الكثيف
الترميز بالزاوية الكثيف (DAE) هو مزيج من الترميز بالزاوية والترميز الطوري. يتيح الترميز بالزاوية الكثيف ترميز قيمتَي ميزتين في كيوبت واحد: زاوية واحدة بدوران حول المحور Y، والأخرى بدوران حول المحور : . يُرمِّز الميزتين على النحو التالي:
ترميز ميزتَين في كيوبت واحد يؤدي إلى تقليل عدد الكيوبتات المطلوبة للترميز بمقدار . وبتوسيع هذا ليشمل ميزات أكثر، يمكن ترميز متجه البيانات على النحو التالي:
يمكن تعميم الترميز بالزاوية الكثيف ليشمل دوال عشوائية للميزتين بدلاً من الدوال المثلثية المستخدمة هنا، وهذا ما يُعرف بالترميز العام للكيوبت[7].
كمثال على الترميز بالزاوية الكثيف، يُرمِّز الكود أدناه ويُصوِّر ترميز الميزتين و.
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

تحقق من فهمك
اقرأ الأسئلة أدناه، فكّر في إجاباتك، ثم انقر على المثلثات لعرض الحلول.
بناءً على ما سبق، كم عدد الكيوبتات اللازمة لترميز 6 ميزات باستخدام الترميز الكثيف؟
الجواب: 3
اكتب كوداً لتحميل المتجه باستخدام الترميز بالزاوية الكثيف.
الجواب:
لاحظ أننا أضفنا "0" إلى القائمة لتجنب مشكلة وجود معامل غير مستخدم في مخطط الترميز الخاص بنا.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

الترميز باستخدام خرائط الميزات المدمجة
الترميز عند نقاط عشوائية
يُعِدّ الترميز بالزاوية، والترميز الطوري، والترميز الكثيف حالات جداء مع ترميز ميزة على كل كيوبت (أو ميزتين لكل كيوبت). وهذا يختلف عن الترميز الأساسي والترميز بالسعة، إذ تستخدم هذه الطرق حالات متشابكة، ولا توجد علاقة 1:1 بين ميزة البيانات والكيوبت. في الترميز بالسعة مثلاً، قد تكون إحدى الميزات هي سعة الحالة وأخرى هي سعة الحالة . بشكل عام، الطرق التي تُرمِّز في حالات الجداء تُنتج دوائر أكثر ضحالة ويمكنها تخزين ميزة واحدة أو ميزتين على كل كيوبت. أما الطرق التي تستخدم التشابك وتربط ميزة بحالة بدلاً من كيوبت فتُنتج دوائر أعمق، ويمكنها تخزين ميزات أكثر لكل كيوبت في المتوسط.
لكن لا يجب أن يكون الترميز كاملاً في حالات الجداء أو كاملاً في الحالات المتشابكة كما في الترميز بالسعة. بل إن كثيراً من مخططات الترميز المدمجة في Qiskit تتيح الترميز قبل طبقة التشابك وبعدها، بدلاً من الاقتصار على البداية فقط. يُعرف هذا بـ"إعادة رفع البيانات". للاطلاع على أعمال ذات صلة، راجع المراجع [5] و[6].
في هذا القسم، سنستخدم ونُصوِّر بعض مخططات الترميز المدمجة. جميع الطرق في هذا القسم تُرمِّز ميزة على شكل دورانات على بوابة ذات معاملات على كيوبت، حيث . لاحظ أن تعظيم تحميل البيانات لعدد معين من الكيوبتات ليس الاعتبار الوحيد؛ ففي كثير من الحالات قد يكون عمق الدائرة اعتباراً أهم من عدد الكيوبتات.
Efficient SU2
مثال شائع ومفيد على الترميز مع التشابك الكمي هو دائرة efficient_su2 في Qiskit. والمثير للإعجاب أن هذه الدائرة تستطيع، على سبيل المثال، ترميز 8 ميزات على 2 كيوبت فقط. دعنا نشاهد ذلك ثم نحاول أن نفهم كيف يكون هذا ممكنًا.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

حين نكتب الحالة، سنتبع اصطلاح Qiskit الذي يرتّب الكيوبتات الأقل أهمية في أقصى اليمين، كما في أو قد تصبح هذه الحالات معقدة جدًا بسرعة كبيرة، وهذا المثال النادر قد يفسّر لماذا نادرًا ما تُكتب مثل هذه الحالات بصورة صريحة.
يبدأ نظامنا في الحالة وحتى الحاجز الأول (النقطة التي نسمّيها )، تكون حالاتنا:
هذا مجرد ترميز كثيف رأيناه من قبل. الآن بعد بوابة CNOT، عند الحاجز الثاني ()، تكون حالتنا:
الآن نطبّق المجموعة الأخيرة من دورانات الكيوبت الواحد ونجمع الحالات المتشابهة للحصول على:
هذه المعادلة على الأرجح معقدة جدًا لتحليلها. بدلًا من ذلك، تراجع خطوة للوراء وفكّر في عدد المعاملات التي حمّلناها على الحالة: ثمانية. لكننا لدينا فقط أربع حالات أساسية حسابية. قد يبدو للوهلة الأولى أننا حمّلنا معاملات أكثر مما هو منطقي، إذ يمكن كتابة الحالة النهائية على النحو . لاحظ مع ذلك أن كل معامل مسبق هو عدد مركّب! وإذا كُتب على هذا الشكل:
يتضح أن لدينا فعلًا ثمانية معاملات على الحالة يمكننا ترميز ثماني ميزات عليها.
بزيادة عدد الكيوبتات وزيادة عدد تكرارات طبقات التشابك والدوران، يمكن ترميز كميات أكبر بكثير من البيانات. كتابة دوال الموجة يصبح سريعًا أمرًا غير قابل للتطبيق. لكن لا يزال بإمكاننا مشاهدة الترميز في العمل.
نرمّز هنا متجه البيانات ذا 12 ميزة على دائرة efficient_su2 ذات 3 كيوبتات، مستخدمين كل بوابة معلمة لترميز ميزة مختلفة.
في متجه البيانات هذا، تظهر الميزات بترتيب معين. بمعزل عن السياق، لا يهم إن رُمّزت بهذا الترتيب أو بالعكس. المهم هو تتبّع الترتيب والتناسق فيه. لاحظ في مخطط الدائرة أن efficient_su2 يفترض ترتيبًا معينًا للترميز، وتحديدًا يملأ طبقة البوابات المعلمة الأولى من الكيوبت 0 إلى الكيوبت 2، ثم ينتقل إلى الطبقة التالية. هذا لا يتعارض ولا يتوافق بالضرورة مع ترميز little-endian، إذ لا يمكن دائمًا ترتيب ميزات البيانات حسب الكيوبت مسبقًا قبل تحديد دائرة الترميز.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

بدلًا من زيادة عدد الكيوبتات، قد تختار زيادة عدد تكرارات طبقات التشابك والدوران. لكن هناك حدود لعدد التكرارات المفيدة. كما أُشير سابقًا، ثمة مقايضة: الدوائر التي تحتوي على كيوبتات أكثر أو تكرارات أكثر لطبقات التشابك والدوران قد تخزّن معاملات أكثر، لكنها تفعل ذلك بعمق دائرة أكبر. سنعود إلى أعماق بعض خرائط الميزات المدمجة لاحقًا. طرق الترميز التالية المدمجة في Qiskit تتضمن "feature map" في أسمائها. دعنا نؤكد من جديد أن ترميز البيانات في دائرة كمومية هو في حد ذاته تعيين للميزات، بمعنى أنه ينقل البيانات إلى فضاء جديد: فضاء هيلبرت للكيوبتات المعنية. العلاقة بين بُعد فضاء الميزات الأصلي وبُعد فضاء هيلبرت ستعتمد على الدائرة المستخدمة في الترميز.
خريطة ميزات
يمكن تفسير خريطة ميزات (ZFM) باعتبارها امتدادًا طبيعيًا لترميز الطور. تتكوّن ZFM من طبقات متناوبة من بوابات الكيوبت الواحد: طبقات بوابة هادامار وطبقات بوابة الطور. ليكن متجه البيانات يحتوي على ميزة. تُمثَّل الدائرة الكمومية التي تنفّذ تعيين الميزات كمؤثر أحادي يعمل على الحالة الابتدائية:
حيث هي الحالة الأرضية لـ كيوبت. يُستخدم هذا الترميز للتناسق مع المرجع [4] لـ Havlicek et al. تُعيَّن ميزات البيانات بصورة واحد-لواحد مع الكيوبتات المقابلة. على سبيل المثال، إن كانت لديك 8 ميزات في متجه بيانات، فستستخدم 8 كيوبتات. تتكوّن دائرة ZFM من تكرار لدائرة فرعية مؤلفة من طبقات بوابة هادامار وطبقات بوابة الطور. طبقة هادامار تتألف من بوابة هادامار تعمل على كل كيوبت في سجلّ -كيوبت، ، ضمن المرحلة ذاتها من الخوارزمية. ينطبق هذا الوصف أيضًا على طبقة بوابة الطور حيث يتأثر الكيوبت بـ . كل بوابة لها ميزة واحدة كمعطى، لكن طبقة بوابة الطور () هي دالة لمتجه البيانات. المؤثر الأحادي الكامل لدائرة ZFM بتكرار واحد هو:
ثم تكرارات من هذا المؤثر الأحادي تكون:
ميزات البيانات، ، تُعيَّن إلى بوابات الطور بالطريقة ذاتها في جميع التكرارات الـ . حالة خريطة ميزات ZFM هي حالة جداء وهي فعّالة للمحاكاة الكلاسيكية[4].
للبدء بمثال صغير، نبرمج دائرة ZFM ذات كيوبتين في Qiskit ونرسمها لإظهار البنية البسيطة للدائرة. في هذا المثال، يُنفَّذ تكرار واحد، ، مع متجه البيانات . لاحظ أن هذا مكتوب بالترتيب المعياري لمتجه في Python، أي أن العنصر هو لنا حرية ترميز هذه الميزة على الكيوبت ، أو على الكيوبت . مجددًا، لا يمكن دائمًا وجود تعيين 1:1 واحد من ترتيب الميزات إلى ترتيب الكيوبتات، إذ تُرمَّز أعداد مختلفة من الميزات على كل كيوبت في خرائط ميزات مختلفة. ومجددًا ما يهم هو أن نكون واعين بمكان ترميز كل ميزة. عند تقديم قائمة معاملات لخريطة ميزات ، ستُرمَّز الميزة 0 من القائمة على الكيوبت الأقل أهمية الذي يحتوي بوابة معلمة، أي الكيوبت 0. لذا سنتبع هذا الاصطلاح حين نفعل ذلك يدويًا. سنرمّز على الكيوبت ، و على الكيوبت .
يعمل مؤثر الدائرة الأحادي لـ ZFM على الحالة الابتدائية بالطريقة التالية:
أُعيدت صياغة المعادلة حول حاصل الضرب التنسيقي للتأكيد على العمليات على كل كيوبت. يستخدم كود Qiskit التالي بوابات هادامار والطور بصورة صريحة لإظهار بنية ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

نرمّز الآن متجه البيانات ذاته على دائرة ZFM بثلاثة تكرارات، ، باستخدام صنف z_feature_map في Qiskit، مما يعطينا في المجمل خريطة الميزات الكمومية . بشكل افتراضي في صنف z_feature_map، تُضرب المعاملات في 2 قبل تعيينها على بوابة الطور . للحصول على الترميزات ذاتها كما في الأعلى، نقسم على 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

من الواضح أن هذا تعيين مختلف عن الذي أجريناه يدويًا أعلاه، لكن لاحظ الاتساق في ترتيب المعاملات: تم تشفير مجددًا على الكيوبت .
يمكنك استخدام ZFM عبر فئة ZFM في Qiskit؛ كما يمكنك الاستلهام من هذا الهيكل لبناء تعيين الميزات الخاص بك.
خريطة ميزات
تمتد خريطة ميزات (ZZFM) على خريطة ZFM بإضافة بوابات تشابك ثنائية الكيوبت، وتحديدًا بوابة دوران وهي . يُعتقد أن ZZFM يصعب حسابها بشكل عام على الحاسوب الكلاسيكي، على عكس ZFM.
تُنفّذ تفاعلًا من نوع وتكون أقصى تشابكًا عند . يمكن تحليل إلى سلسلة من البوابات على كيوبتَين، كما هو موضح في كود Qiskit التالي باستخدام بوابة RZZ وأسلوب الفئة QuantumCircuit المسمى decompose. نقوم بتشفير ميزة واحدة من متجه البيانات :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

كما هو الحال في الغالب، نرى هذا ممثلًا كوحدة تشبه بوابة واحدة، حتى نستخدم .decompose() لرؤية جميع البوابات المكوِّنة لها.
qc.decompose().draw("mpl", scale=1)

يتم تعيين البيانات بدوران طوري على الكيوبت الثاني. تقوم بوابة بتشابك الكيوبتَين اللذَين تعمل عليهما بدرجة تشابك تحددها قيمة الميزة المُشفَّرة.
تتكوّن دائرة ZZFM الكاملة من بوابة هادامار وبوابة طور، كما في ZFM، يعقبها التشابك الموصوف أعلاه. تكرار واحد لدائرة ZZFM هو:
حيث تحتوي على طبقة بوابات ZZ منظَّمة وفق مخطط تشابك معين. يُعرض عدة مخططات تشابك في كتل الكود أدناه. يتضمن هيكل أيضًا دالة تجمع ميزات البيانات من الكيوبتات المتشابكة على النحو التالي. لنفترض أن بوابة ستُطبَّق على الكيوبتَين و. في طبقة الطور، تحتوي هذه الكيوبتات على بوابات طور تُشفّر و عليها على التوالي. الوسيط لـ لن يكون مجرد إحدى هذه الميزات أو الأخرى، بل دالة تُشار إليها في الغالب بـ (لا يجب الخلط بينها وبين الزاوية الاستوائية):
سنرى هذا في أمثلة عدة أدناه. امتداد التكرارات المتعددة هو نفسه كما في حالة z_feature_map:
بما أن العوامل قد ازدادت تعقيدًا، فلنبدأ بتشفير متجه بيانات باستخدام ZZFM ثنائي الكيوبت وتكرار واحد بالكود التالي:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

افتراضيًا في Qiskit، يتم تعيين الميزتَين معًا إلى بواسطة دالة التعيين هذه . يتيح Qiskit للمستخدم تخصيص الدالة (أو حيث هي مجموعة أزواج الكيوبتات المقترنة عبر بوابات ) كخطوة معالجة مسبقة.
بالانتقال إلى متجه بيانات رباعي الأبعاد وتعيينه إلى ZZFM رباعي الكيوبتات مع تكرار واحد، يمكننا البدء في رؤية التعيين لأزواج الكيوبتات المختلفة. كما يمكننا أن نرى معنى التشابك "الخطي":
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

في مخطط التشابك الخطي، يتم تشابك أزواج الكيوبتات المتجاورة (المرقَّمة) في هذه الدائرة. ثمة مخططات تشابك مدمجة أخرى في Qiskit، منها circular وfull.
خريطة ميزات باولي
خريطة ميزات باولي (PFM) هي تعميم لـ ZFM وZZFM لاستخدام بوابات باولي اعتباطية. تأخذ خريطة ميزات باولي شكلًا مشابهًا جدًا لخريطتَي الميزات السابقتَين. لـ تكرار لتشفير الـ ميزة لمتجه
بالنسبة لـ PFM، يتم تعميم إلى معامل أحادي لتوسعة باولي. نقدم هنا صيغة أكثر عمومية لخرائط الميزات التي درسناها حتى الآن:
حيث هو معامل باولي، . هنا هي مجموعة جميع ترابطات الكيوبتات كما تحددها خريطة الميزات، بما في ذلك مجموعة الكيوبتات التي تعمل عليها البوابات أحادية الكيوبت. أي أنه في خريطة ميزات يُعمل فيها على الكيوبت 0 ببوابة طور، وعلى الكيوبتَين 2 و3 ببوابة ، ستتضمن المجموعة العنصرَين . يمر عبر جميع عناصر تلك المجموعة. في خرائط الميزات السابقة، كانت الدالة تتعامل إما حصرًا مع البوابات أحادية الكيوبت أو حصرًا مع البوابات ثنائية الكيوبت. نعرّفها هنا بشكل عام:
للاطلاع على التوثيق، راجع توثيق فئة Pauli feature map في Qiskit). في ZZFM، يُقيَّد المعامل بـ .
أحد أوجه فهم المعامل الأحادي أعلاه هو القياس بالمنتشر في نظام فيزيائي. المعامل الأحادي أعلاه هو معامل تطور أحادي، ، لهاميلتوني مشابه لنموذج إيزينغ، حيث يُستبدل معامل الزمن بقيم البيانات لدفع التطور. توسعة هذا المعامل الأحادي تعطينا دائرة PFM. يمكن تفسير ترابطات التشابك في كاقترانات إيزينغ في شبكة دورانية.
لنأخذ مثالًا على معاملَي باولي و يمثلان تفاعلات من نوع إيزينغ. يوفر Qiskit فئة pauli_feature_map لإنشاء PFM باختيار بوابات أحادية و-كيوبت، والتي ستُمرَّر في هذا المثال كسلاسل باولي 'Y' و'XX'. عادةً ما يكون هو 1 أو 2 للتفاعلات أحادية وثنائية الكيوبت على التوالي. مخطط التشابك هو "linear"، أي أنه يتم اقتران الكيوبتات المتجاورة فقط في الدائرة الكمومية. لاحظ أن هذا لا يتوافق بالضرورة مع الكيوبتات المتجاورة على الحاسوب الكمومي نفسه، إذ إن هذه الدائرة الكمومية هي طبقة تجريدية.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

يوفر Qiskit معاملًا في خرائط ميزات باولي للتحكم في مقياس دورانات باولي.
القيمة الافتراضية لـ هي . بتحسين قيمته في النطاق، مثلًا يمكن محاذاة نواة كمومية مع البيانات بشكل أفضل.
معرض خرائط ميزات باولي
هنا نُصوِّر خرائط ميزات باولي المتنوعة لدوائر ثنائية الكيوبت للحصول على صورة أوضح عن نطاق الاحتمالات.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
يمكن بالطبع توسيع ما سبق ليشمل تباديل وتكرارات أخرى لمصفوفات باولي. نشجع المتعلمين على تجربة تلك الخيارات.
مراجعة خرائط الميزات المدمجة
رأيت عدة مخططات لترميز البيانات في دائرة كمومية:
- الترميز الأساسي
- ترميز السعة
- ترميز الزاوية
- ترميز الطور
- الترميز الكثيف
ورأيت كيف تبني خرائط ميزاتك الخاصة باستخدام هذه المخططات، فضلاً عن أربع خرائط ميزات مدمجة تستفيد من ترميز الزاوية والطور:
- Efficient SU2
- خريطة ميزات Z
- خريطة ميزات ZZ
- خريطة ميزات باولي
تختلف هذه الخرائط المدمجة عن بعضها من عدة نواحٍ:
- العمق لعدد معيّن من الميزات المرمّزة
- عدد الكيوبتات المطلوبة لعدد معيّن من الميزات
- درجة التشابك (وهي مرتبطة بالاختلافات الأخرى بطبيعة الحال)
الكود أدناه يطبّق هذه الخرائط الأربع المدمجة على ترميز مجموعة ميزات، ويرسم عمق بوابتين كيوبت في الدائرة الناتجة. بما أن معدلات أخطاء بوابات الكيوبتين أعلى بكثير من معدلات أخطاء بوابات الكيوبت الواحد، فقد يكون الأكثر أهمية هو عمق بوابات الكيوبتين. في الكود أدناه، نحصل على أعداد جميع البوابات في الدائرة بتحليلها أولاً ثم استخدام count_ops()، كما هو موضح أدناه. بوابات الكيوبتين التي نهتم بها هنا هي بوابات cx:
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
بشكل عام، ستؤدي خرائط ميزات باولي وZZ إلى عمق دائرة أكبر وعدد أعلى من بوابات الكيوبتين مقارنةً بـ efficient_su2 وخرائط ميزات Z.
بما أن خرائط الميزات المدمجة في Qiskit واسعة التطبيق، فغالباً لن نحتاج إلى تصميم خرائطنا الخاصة، لا سيما في مرحلة التعلم. غير أن المتخصصين في تعلم الآلة الكمومي سيعودون على الأرجح إلى موضوع تصميم خرائطهم الخاصة حين يواجهون تحديَّين معقدَّين:
-
الأجهزة الحديثة: وجود الضوضاء والتكلفة الكبيرة لكود تصحيح الأخطاء يعني أن التطبيقات الحالية ستحتاج إلى مراعاة أمور مثل كفاءة الأجهزة وتقليل عمق بوابات الكيوبتين.
-
الخرائط التي تناسب المشكلة المطروحة: شيء واحد أن نقول إن
zz_feature_mapمثلاً يصعب محاكاتها كلاسيكياً وبالتالي هي مثيرة للاهتمام، وشيء آخر تماماً أن تكونzz_feature_mapمناسبة بشكل مثالي لمهمة تعلم الآلة أو مجموعة البيانات الخاصة بك. أداء الدوائر الكمومية ذات المعاملات المختلفة على أنواع مختلفة من البيانات هو مجال بحث نشط.
نختتم بملاحظة حول كفاءة الأجهزة.
ترميز الميزات المتوافق مع الأجهزة
ترميز الميزات المتوافق مع الأجهزة هو الذي يأخذ في الاعتبار قيود الحواسيب الكمومية الحقيقية، بهدف تقليل الضوضاء والأخطاء في الحساب. عند تشغيل الدوائر الكمومية على الحواسيب الكمومية قريبة المدى، توجد استراتيجيات عديدة للتخفيف من الضوضاء المتأصلة في الأجهزة. إحدى الاستراتيجيات الرئيسية لكفاءة الأجهزة هي تقليل عمق الدائرة الكمومية حتى تحظى الضوضاء وفقدان الترابط بوقت أقل لإفساد الحساب. عمق الدائرة الكمومية هو عدد خطوات البوابات المتزامنة المطلوبة لإتمام الحساب كاملاً (بعد تحسين الدائرة)[5]. تذكّر أن عمق الدائرة المجردة المنطقية قد يكون أقل بكثير من العمق بعد تحويل الدائرة للتشغيل على حاسوب كمومي حقيقي.
التحويل (Transpilation) هو عملية تحويل الدائرة الكمومية من تجريد عالي المستوى إلى دائرة جاهزة للتشغيل على حاسوب كمومي حقيقي، مع مراعاة قيود الأجهزة. للحاسوب الكمومي مجموعة أصلية من بوابات الكيوبت الواحد والكيوبتين، مما يعني أن جميع البوابات في كود Qiskit يجب تحويلها إلى مجموعة البوابات الأصلية للأجهزة. على سبيل المثال، في ibm_torino، وهو معالج كمومي يعمل بمعالج Heron r1 واكتمل عام 2023، البوابات الأصلية أو الأساسية هي {CZ, ID, RZ, SX, X}. وهذه هي بوابة CZ ذات الكيوبتين المتحكَّم بها، وبوابات كيوبت واحد تُسمى الهوية، ودوران ، والجذر التربيعي لـ NOT، وNOT على التوالي، مما يوفر مجموعة شاملة. عند تنفيذ بوابات متعددة الكيوبتات كدائرة فرعية مكافئة، تكون بوابات الفيزيائية ذات الكيوبتين ضرورية، إلى جانب بوابات كيوبت واحد أخرى متاحة في الأجهزة. علاوة على ذلك، لإجراء بوابة كيوبتين على زوج من الكيوبتات غير المترابطة فيزيائياً، تُضاف بوابات SWAP لنقل حالات الكيوبت بين الكيوبتات لتمكين الاقتران، مما يؤدي إلى امتداد حتمي للدائرة. باستخدام وسيط optimization الذي يمكن ضبطه من 0 حتى أعلى مستوى وهو 3. للتحكم الأكبر وإمكانية التخصيص، يمكن إدارة مسار المحوّل باستخدام Qiskit Pass Manager. راجع توثيق Qiskit Transpiler لمزيد من المعلومات حول التحويل.
في Havlicek وآخرين 2019 [2]، إحدى الطرق التي حقق بها المؤلفون كفاءة الأجهزة هي استخدام خريطة ميزات لأنها توسع من الرتبة الثانية (انظر قسم "خريطة ميزات " أعلاه). التوسع من الرتبة يحتوي على بوابات -كيوبت. الحواسيب الكمومية من IBM® لا تمتلك بوابات -كيوبت أصلية حيث ، لذا فإن تنفيذها يتطلب التحليل إلى بوابات CNOT ذات الكيوبتين المتاحة في الأجهزة. الطريقة الثانية التي يقلل بها المؤلفون العمق هي اختيار طوبولوجيا اقتران تتوافق مباشرة مع اقترانات البنية. تحسين إضافي يقومون به هو استهداف دائرة فرعية أجهزة عالية الأداء ذات اتصال مناسب. أشياء إضافية تستحق المراعاة هي تقليل عدد تكرارات خريطة الميزات واختيار مخطط تشابك منخفض العمق أو "خطي" مخصص بدلاً من المخطط "الكامل" الذي يشابك جميع الكيوبتات.

يُظهر الرسم البياني أعلاه شبكة من العقد والحواف التي تمثل الكيوبتات الفيزيائية واقترانات الأجهزة على التوالي. تُعرض خريطة الاقتران وأداء ibm_torino مع جميع بوابات اقتران CZ ذات الكيوبتين الممكنة. الكيوبتات مُرمَّزة بالألوان على مقياس مبني على وقت الاسترخاء T1 بالميكروثانية (μs)، حيث تكون أوقات T1 الأطول أفضل وذات ظل فاتح. حواف الاقتران مُرمَّزة بالألوان حسب خطأ CZ، حيث تكون الظلال الأغمق أفضل. يمكن الوصول إلى معلومات مواصفات الأجهزة في مخطط تكوين الواجهة الخلفية للأجهزة IBMQBackend.configuration().
المراجع
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()